
Kafka--Consumer消费者
Kafka 的 consumer 是以pull的形式获取消息数据的。 producer push消息到kafka cluster ,consumer从集群中pull消息,如下图。该博客主要讲解. Parts在消费者中的分配、以及相关的消费者顺序、底层结构元数据信息、Kafka数据读取和存储等。

Parts在消费者中的分配
- 首先partition和consumer都会字典排序
- 分区Partition从小到大排序:分区顺序是0,1,2,3,4,5,6,7,8,9
- 消费者Consumer id按照字典顺序排序:f0b87809-0, f1b87809-0, f1b87809-1
- 如何计算分区
- 首先确认最少分区数: partition/consumer
- 再确定额外分配数: partition%consumer
源码算法:
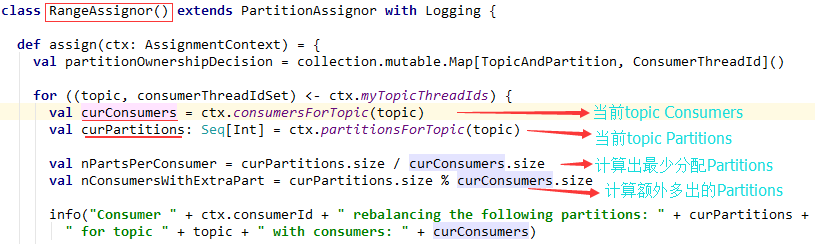
比如:有4个partition,3个consumer,这第一个就会分配2个,其他会分配一个。下面我们来演示一下Kafka强大的平衡机制吧(就是看看怎麼自動分配partition,同一topic):
1
2
3
4
5
6
7#######################下面是我们有4个Partition###################################
[root@xxo08 kafka]# bin/kafka-topics.sh --describe --zookeeper xxo08:2181,xxo09:2181,xxo10:2181 --topic world
Topic:world PartitionCount:4 ReplicationFactor:3 Configs:
Topic: world Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: world Partition: 1 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: world Partition: 2 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: world Partition: 3 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
当我们只有1个consumer时:

我们接着再启动一个consumer

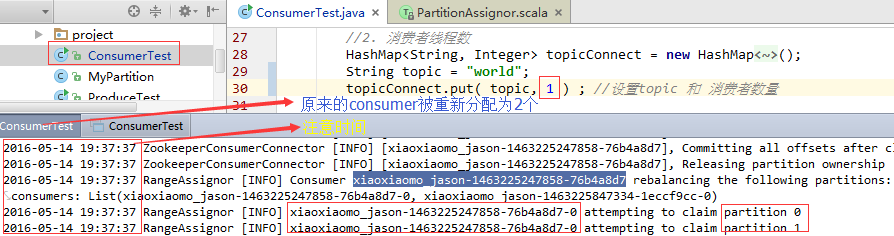
大家明白了吧,我就不再继续启动了。增加或减少,consumer都会触发分区,重新分区。
消费者顺序
- 消费顺序对于组来说:
- 每一个消费者之间是无序的。
- 同一个消费者对应一个Partition是offset有序的。
- 同一个消费者对应多个Partition是顺序消费至最新状态。
- 演示1:同一个消费者对应一个Partition是offset有序的
1
2
3
4
5
6
7
8#######################创建1个partition###################################
[root@xxo08 kafka]# bin/kafka-topics.sh --create --zookeeper xxo08:2181,xxo09:2181,xxo10:2181 --replication-factor 3 --partitions 1 --topic hello
Created topic "hello".
#######################查看 partition ###################################
[root@xxo08 kafka]# bin/kafka-topics.sh --describe --zookeeper xxo08:2181,xxo09:2181,xxo10:2181 --topic hello
Topic:hello PartitionCount:1 ReplicationFactor:3 Configs:
Topic: hello Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2

- 演示2:同一个消费者对应多个Partition是顺序消费至最新状态
1
2
3
4
5
6
7
8
9
10
11#######################继续增加2个partition################################
[root@xxo08 kafka]# bin/kafka-topics.sh --alter --zookeeper xxo08:2181,xxo09:2181,xxo10:2181 -partitions 3 --topic hello
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!
#######################查看 partition ###################################
[root@xxo08 kafka]# bin/kafka-topics.sh --describe --zookeeper xxo08:2181,xxo09:2181,xxo10:2181 --topic hello
Topic:hello PartitionCount:3 ReplicationFactor:3 Configs:
Topic: hello Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: hello Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: hello Partition: 2 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1

Kafka底层结构
- 分爲兩個部分
- broker :简单理解为topic的元数据信息(topics,ids),包含topic的分区情况、leader、状态、数据大小、地址端口、版本
- consumer :消费者的元数据信息,重点就是offset了。
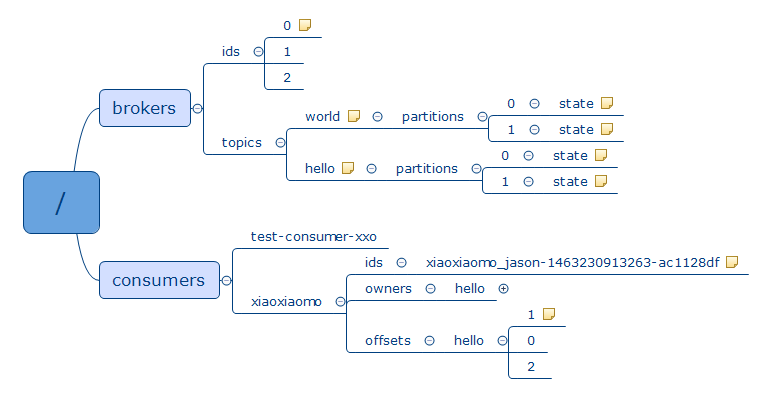
Broker元数据
topics
ids

Consumer元数据
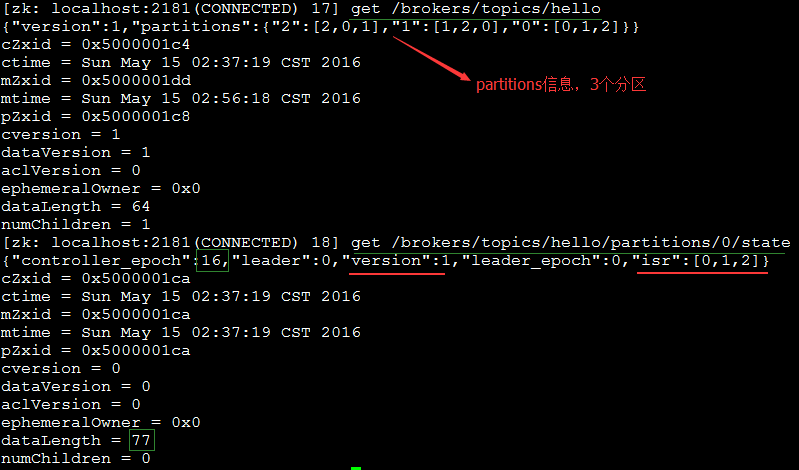
Partition:为了实现扩展性,一个非常大的topic可以分布到多个 broker 上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息 都会被分配一个有序的id(offset)。从上面示例我们也可以看出kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体 (多个partition间)的顺序。

分区就是一个有序的,不可变的消息队列.新来的commit log持续往后面加数据.这些消息被分配了一个下标(或者偏移),就是offset,用来定位这一条消息。
offset
从上面得知,partition自己维护了一个offset,我们知道zk中保留了kafka的元数据信息。下面我们来看一下底层结构运行/opt/zookeeper/bin/zkCli.sh :

注意:上图中offset=18不是即使更新到zk中的,默认是一分钟,可以设置:
1
2
3
4
5
6#########true时,Consumer会在消费消息后将offset同步到zookeeper################
#########当Consumer失败后,新的consumer就能从zookeeper获取最新的offset#########
auto.commit.enable = true
#########自动提交的时间间隔(默认如下60秒)#####################################
auto.commit.interval.ms = 60 * 1000
owners
- 里面存放了消费者ID

ids
ids: Consumer进程id,每一个consumer进程就有一个id(每一个进程可以设置多个consumer线程)。
- 我们再来查看一下ids:

Kafka数据读取/存储
- 先看一下本地log目录的分区文件夹,如下(我的kafka存储的数据比较小,对应的partition都为0。该segment可以设置:log.segment.bytes,制日志segment文件的大小,超出该大小则追加到一个新的日志segment文件中(-1表示没有限制)):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26[root@xxo08 kafka]# tree ../kafka-logs/
../kafka-logs/
├── hello-0
│ ├── 00000000000000000000.index ##索引文件
│ └── 00000000000000000000.log ##日志文件
├── hello-1
│ ├── 00000000000000000000.index
│ └── 00000000000000000000.log
├── hello-2
│ ├── 00000000000000000000.index
│ └── 00000000000000000000.log
├── recovery-point-offset-checkpoint
├── replication-offset-checkpoint
├── world-0
│ ├── 00000000000000000000.index
│ └── 00000000000000000000.log
├── world-1
│ ├── 00000000000000000000.index
│ └── 00000000000000000000.log
├── world-2
│ ├── 00000000000000000000.index
│ └── 00000000000000000000.log
└── world-3
├── 00000000000000000000.index
└── 00000000000000000000.log
7 directories, 16 files
存储策略
partition存储的时候,分成了多个segment(段),然后通过一个index,索引,来标识第几段.
- 具体的流程:
发布者发到某个topic的 消息会被分布到多个partition上(随机或根据用户指定的函数进行分布),broker收到发布消息往对应partition的最后一个segment上添加 该消息,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
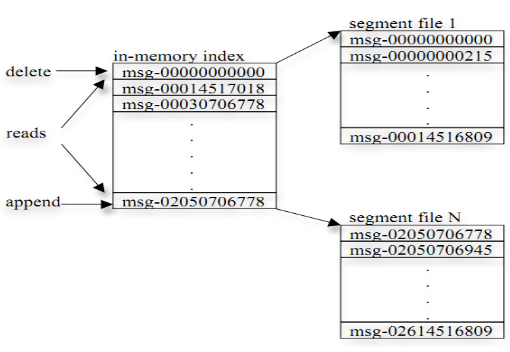
高效读取
- kafka高效读取有两个重要的东西,分段和索引。

每个片段一个文件并且此文件以该片段中最小的offset命名,查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中。
为每个分段后的数据文件建立了索引文件(index),存储了【offset和message在文件中的position】。index中采用了稀疏存储。
- 具体查找方法:
1
2
3
4
5###############比如我们有文件,需要查找2016的文件##################
00000000000000000000.index
00000000000000000000.log
00000000000000002000.index
00000000000000002000.log
- 首先通过zk的元数据信息找到(position、broker、topic)然后我们就能在Partition的内存索引中根据offset 2016找到到相应topic的文件位置和index文件。
- 把index文件加载到内容中,然后开始读取。
- 由于是稀疏索引所以相对来说节约空间,跳跃式的查找然后进一步找到2016,读取到对应的posistion。
- 最后通过posistion去找到message数据。