
Flume--集群及项目实战
本篇博客主要讲解flume集群的搭建及项目实战,flume集群相对来说比较简单,重点是后面的项目实战。如果对flume还不够理解或者它的组件不熟悉可以阅读上篇博客:http://blog.xiaoxiaomo.com/2016/05/22/Flume-日志收集/
Flume 集群
- 解压缩 : tar -zxvf apache-flume-1.6.0-bin.tar.gz -C /opt/ ;
- 重命名 : mv /opt/apache-flume-1.6.0-bin/ /opt/flume(可省略) ;
- 复制配置文件 : cp conf/flume-env.sh.template conf/flume-env.sh ;
- 修改conf/flume-env.sh : JAVA_HOME ;
- 复制flume到其他节点 : scp -r …… 。
常见架构
- 常见架构

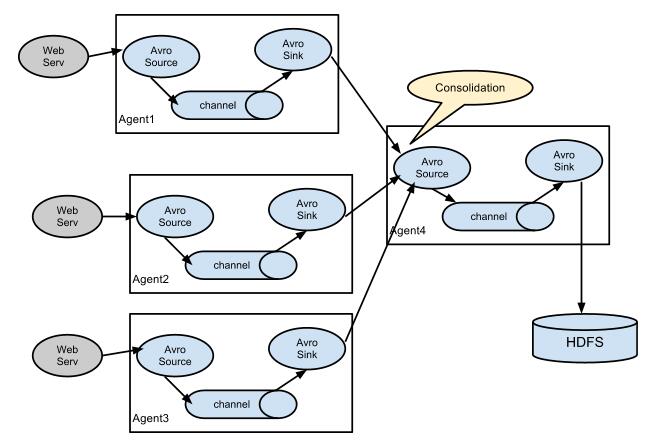

实战
需求
- A、B两台机器实时生产日志主要类型为
access.log、ugcheader.log、ugctail.log, 要求:
- 把A、B 机器中的access.log、ugcheader.log、ugctail.log 汇总到C机器上然后统一收集到hdfs和Kafka中。
- 在hdfs中要求的目录为:用作离线统计。
/source/access/2016-01-01/
/source/ugcheader/2016-01-01/
/source/ugctail/2016-01-01/ - Kafka分topic , 用作实时分析。
画图

准备
机器 (博主使用了三台机器)
A机器 : xxo 08 安装 : zookeeper 、 kafka 、flume
B机器 : xxo 09 安装 : zookeeper 、 kafka 、flume
C机器 : xxo 10 安装 : zookeeper 、 kafka 、flume 、hadoop伪分布式启动
- 启动zookeeper : /opt/zookeeper/bin/zkServer.sh start
- 启动kafka : nohup /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties >>/opt/logs/kafka-server.log 2>&1 &
- 启动hdfs : start-dfs.sh
- 这里查看一下xxo10的进程 :
1
2
3
4
5
6[root@xxo10 flume]# jps
1305 Kafka
1252 QuorumPeerMain
1786 Jps
1542 DataNode
1454 NameNode
- 创建topic
1
2
3
4
5
6
7[root@xxo08 kafka]# bin/kafka-topics.sh --create --zookeeper xxo08:2181,xxo09:2181,xxo10:2181 --replication-factor 3 --partition 3 --topic access
[root@xxo08 kafka]# bin/kafka-topics.sh --create --zookeeper xxo08:2181,xxo09:2181,xxo10:2181 --replication-factor 3 --partition 3 --topic ugchead
[root@xxo08 kafka]# bin/kafka-topics.sh --create --zookeeper xxo08:2181,xxo09:2181,xxo10:2181 --replication-factor 3 --partition 3 --topic ugctail
[root@xxo08 kafka]# bin/kafka-topics.sh --list --zookeeper xxo08:2181,xxo09:2181,xxo10:2181 ###查看
access
ugchead
ugctail
C机器
1 | [root@xxo10 flume]# vim conf/hdfs_kafka.conf |
- 启动
1
2
3
4
5[root@xxo10 ~]# cd /opt/apache-flume/
[root@xxo10 flume]# bin/flume-ng agent --conf conf/ --conf-file conf/hdfs_kafka.conf --name a1 -Dflume.root.logger=INFO,console &
......
......
......Component type: SINK, name: kfk started ##启动成功
A机器
1 | [root@xxo08 flume]# vim conf/hdfs_kafka.conf |
- 启动A机器
1
[root@xxo08 flume]# bin/flume-ng agent --conf conf/ --conf-file conf/hdfs_kafka.conf --name a1 -Dflume.root.logger=INFO,console &
验证功能
- 我这里启动了一个向
access.log、ugcheader.log、ugctail.log添加数据的java程序:1
[root@xxo08 ~]# java -cp KafkaFlumeProject_20160519-1.0-SNAPSHOT-jar-with-dependencies.jar com.xxo.utils.Creator
查看hdfs的情况
1
2
3
4
5
6[root@xxo10 ~]# hdfs dfs -text /source/ugchead/20160523/* | more
1001 221.8.9.6 80 be83f3fd-a218-4f98-91d8-6b4f0bb4558b 750b6203-4a7d-42d5-82e4-906415b70f63 10207 {"ugctype":"consumer",
"userId":"40604","coin":"10","number":"2"} 1463685721663
1003 218.75.100.114 ea11f1d2-680d-4645-a52e-74d5f2317dfd 8109eda1-aeac-43fe-94b1-85d2d1934913 20101 {"ugctype":"fav","user
Id":"40604","item":"13"} 1463685722666
......kafka消费者
1
2
3
4########################## 这里查看一下access ###############################
[root@xxo09 ~]# /opt/kafka/bin/kafka-console-consumer.sh --zookeeper xxo08:2181,xxo09:2181,xxo10:2181 --topic access --from-beginning
1001 218.26.219.186 070c8525-b857-414d-98b6-13134da08401 10201 0 GET /tologin HTTP/1.1 408 /update/pass Mozilla/5.0 (Windows; U; Windows NT 5.1)Gecko/20070803 Firefox/1.5.0.12 1463676319717
......查看日志:
tac /opt/flume/logs/flume.log | more
同步节点
- 【B机器】
1
2
3
4
5
6####################### 拷贝 ##################################
[root@xxo08 flume]# scp /opt/flume/conf/hdfs_kafka.conf root@xxo09:/opt/flume/conf/
hdfs_kafka.conf 100% 1803 1.8KB/s 00:00
####################### 远程启动 ###############################
[root@xxo08 flume]# ssh root@xxo09 "/opt/flume/bin/flume-ng agent --conf /opt/flume/conf/ --conf-file /opt/flume/conf/hdfs_kafka.conf --name a1" &