Hive--数据类型与表
本片博客介绍了数据类型以及数据的映射,主要讲解表,表的创建,表的两种类型(受控表、外部表)。还有分区、桶表和视图。
数据类型
Hive支持的数据类型如下:
- 基本类型
1
2
3
4
5
6tinyint smallint int bigint
boolean
float double
string
binary 字节数组(Hive 0.8.0 以上才可用)
timestamp (Hive 0.8.0 以上才可用)
- 复合类型
1
2
3
4array: array<data_type>
map: map<primitive_type, data_type>
struct: struct<col_name : data_type [COMMENT col_comment], ...>
union: uniontype<data_type, data_type, ...>
数据的映射
在上篇博客中,我们提到:hive将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。那么hive到底是怎么去映射的呢?
- 其实就是:
- 当我们创建一张表时,就生成了metadata到数据库中,表信息保存在一张叫SDS表中,location字段指定了表数据的位置。
- local默认路径为
/user/hive/warehouse/db数据库/表名相同的文件下/目录下面(即使我们直接上传文件到该目录表也能加载)。 - 加载后解析数据,通过默认的分隔符进行解析,行的默认分隔符为“\n”。
- 示例:
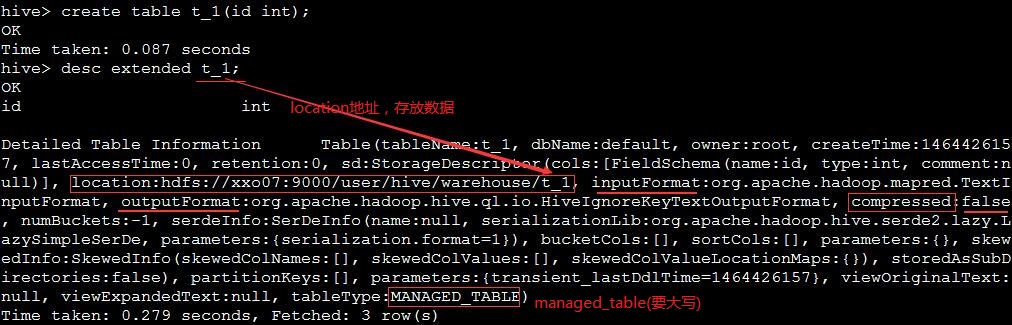
创建一张表
vim写入数据,并上传到hdfs中
1
2
3
4
5
6
7[root@xxo07 data]# momore t_1.txt
1
2
3
4
5
[root@xxo07 data]# hdfs dfs -put t_1.txt /user/hive/warehouse/t_1/查看hdfs

查看我们的表
1
2
3
4
5
6
7
8hive> select * from t_1;
OK
1
2
3
4
5
Time taken: 0.917 seconds, Fetched: 5 row(s)
表
表的创建
- 分隔符
- 通过上面的例子我们知道,数据的映射,并且默认的
行分隔符为“\n”; 列默认分割符为“\001”,collection items默认为“\002”,map keys默认为“\003”,- 创建表时我们可以自定义分隔符。
- hive是读模式,数据库加载数据的时候不进行数据的合法性校验,在查询数据的时候将不合法的数据显示为NULL。这样加载速度快,适合大数据的加载。
示例:下面我们来创建一个学生表的表,有字段
id,name,tel,scores,addrs如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18hive> create database xxo;
OK
Time taken: 0.246 seconds
hive> use xxo;
OK
Time taken: 0.029 seconds
hive> create table t_student(
> id int,
> name string,
> tel array<string>,
> scores map<string,int>,
> addrs struct<home:string,post:int>
> ) row format delimited
> fields terminated by '\t'
> collection items terminated by ','
> map keys terminated by ':';
OK
Time taken: 0.404 seconds注:上面已经指定了,列分隔符为“\t”,数组的items分隔符为“,”,map 的分隔符为“:”。
创建数据
1
2
3
4
5
6[root@xxo07 data]
1 张三 15826008600,02358888 math:99,en:100 重庆,500000
2 李四 15826008601,02358818 math:97,en:10 重庆,500000
3 王五 15826008602,02358828 math:89,en:100 云阳,500600
4 赵六 15826008603,02358838 math:100,en:30 万州,500500
5 田七 15826008604,02358848 math:90,en:80 北京,100000查询数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14###########没有通过hdfs直接上传而是通过hive加载数据#################################
hive> load data local inpath 't_2.txt' overwrite into table t_student;
Loading data to table xxo.t_student
Table xxo.t_student stats: [numFiles=1, numRows=0, totalSize=293, rawDataSize=0]
OK
Time taken: 0.363 seconds
hive> select * from t_student;
OK
1 张三 ["15826008600","02358888"] {"math":99,"en":100} {"home":"重庆","post":500000}
2 李四 ["15826008601","02358818"] {"math":97,"en":10} {"home":"重庆","post":500000}
3 王五 ["15826008602","02358828"] {"math":89,"en":100} {"home":"云阳","post":500600}
4 赵六 ["15826008603","02358838"] {"math":100,"en":30} {"home":"万州","post":500500}
5 田七 ["15826008604","02358848"] {"math":90,"en":80} {"home":"北京","post":100000}
Time taken: 0.178 seconds, Fetched: 5 row(s)
受控表
- 默认我们创建的表为
NAMAGED_TABLE类型,叫做受控表(内部表)。 - 受控表中的数据生命周期受到了表定义的影响,即表删除数据也会同时删除。
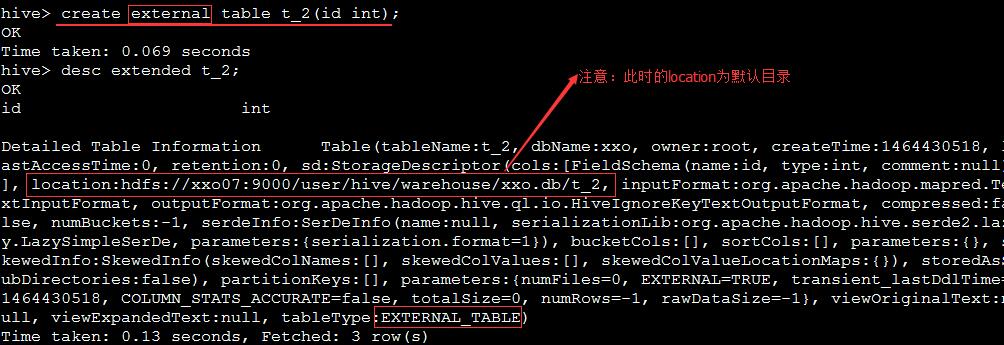
外部表
- 表类型为
EXTERNAL_TABLE数据不受表定义的影响,即删除外部表数据并不会被删除,只会删除,metadata中的数据; 数据加载,就是对外部hdfs上数据的引用。
示例:
创建外部表t_2

加载外部hdfs上的数据

再次查看外部表,发现外部表的location已经改变为我们指定的数据目录


删除t_2表,数据任然在
1
2
3hive> drop table t_2;
OK
Time taken: 0.135 seconds

- 表类型转换

分区表
分区表:包含动态分区与静态分区。注意:分区列不是表中的一个实际的字段,而是一个或者多个伪列。分区表就是将表中的数据按需指定分区字段进行划分,使用分区很方便对数据进行部分查询。
静态分
创建分区表

加载数据


查看hdfs上的数据

- 查看表的partions
1
2
3
4
5hive> show partitions t_5;
OK
dt=2016-05-28/city=cq
dt=2016-05-29/city=bj
Time taken: 0.109 seconds, Fetched: 2 row(s)
动态分区
- 示例:
创建临时表,并加载数据到临时表


动态分区
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48hive> insert overwrite table t_5 partition(dt,city) select t.id,t.dt,t.city from tmp t;
Query ID = root_20160528201717_4d5a2424-ad99-43bb-a480-c0c6c1df3517
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1464437918991_0001, Tracking URL = http://xxo07:8088/proxy/application_1464437918991_0001/
Kill Command = /usr/local/hadoop-2.6.0/bin/hadoop job -kill job_1464437918991_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2016-05-28 20:19:16,822 Stage-1 map = 0%, reduce = 0%
2016-05-28 20:19:38,275 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.26 sec
MapReduce Total cumulative CPU time: 2 seconds 260 msec
Ended Job = job_1464437918991_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://xxo07:9000/tmp/hive/root/7157795c-3864-480e-b89b-abaaacc4740e/hive_2016-05-28_20-17-54_291_6680117664647621540-1/-ext-10000
Loading data to table xxo.t_5 partition (dt=null, city=null)
Time taken for load dynamic partitions : 1023
Loading partition {dt=2015-05-30, city=wz}
Loading partition {dt=2015-05-30, city=hz}
Loading partition {dt=2015-05-30, city=bj}
Loading partition {dt=2015-05-30, city=yy}
Loading partition {dt=2015-05-30, city=cq}
Time taken for adding to write entity : 12
Partition xxo.t_5{dt=2015-05-30, city=bj} stats: [numFiles=1, numRows=1, totalSize=2, rawDataSize=1]
Partition xxo.t_5{dt=2015-05-30, city=cq} stats: [numFiles=1, numRows=1, totalSize=2, rawDataSize=1]
Partition xxo.t_5{dt=2015-05-30, city=hz} stats: [numFiles=1, numRows=1, totalSize=2, rawDataSize=1]
Partition xxo.t_5{dt=2015-05-30, city=wz} stats: [numFiles=1, numRows=1, totalSize=2, rawDataSize=1]
Partition xxo.t_5{dt=2015-05-30, city=yy} stats: [numFiles=1, numRows=1, totalSize=2, rawDataSize=1]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 2.26 sec HDFS Read: 290 HDFS Write: 287 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 260 msec
OK
Time taken: 109.86 seconds
#####################查询数据########################################
hive> select * from t_5 where dt='2015-05-30';
OK
7 2015-05-30 bj
5 2015-05-30 cq
9 2015-05-30 hz
1 2015-05-30 wz
2 2015-05-30 yy
Time taken: 0.094 seconds, Fetched: 5 row(s)
hive> select * from t_5 where city='yy';
OK
2 2015-05-30 yy
Time taken: 0.075 seconds, Fetched: 1 row(s)直观浏览一下
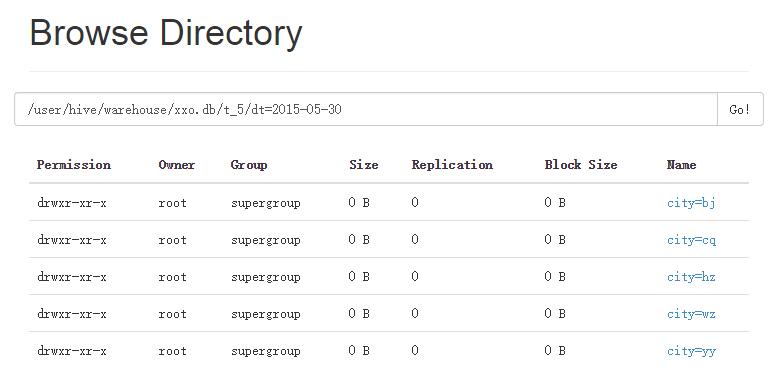
桶表
桶表 : 就是相对均匀的存放数据,每张表查询起来效率都差不多。
- 桶表是对数据进行哈希取值,然后放到不同文件中存储;
- 数据都来源于现有的表中;
- 用途 : 在做多表关联时,为了提高查询效率;或做抽样。
- 示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43bashhive> create table t_bucket(id int) clustered by (id) into 3 buckets;
OK
Time taken: 0.377 seconds
hive> set hive.enforce.bucketing = true; ##设置支持桶表
############################导入数据############################################
hive> insert into table t_bucket select id from t_4;
Automatically selecting local only mode for query
Query ID = root_20160528205252_4ba59e97-c11b-45ad-bdd0-11fb8d2bebd8
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0
2016-05-28 20:52:36,063 Stage-1 map = 0%, reduce = 0%
2016-05-28 20:52:37,130 Stage-1 map = 100%, reduce = 0%
Ended Job = job_local98714577_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://xxo07:9000/tmp/hive/root/9b9b6fa1-9f00-4635-be4d-ac4ac635d546/hive_2016-05-28_20-52-30_591_4317152904230482106-1/-ext-10000
Loading data to table xxo.t_bucket
Table xxo.t_bucket stats: [numFiles=4, numRows=10, totalSize=24, rawDataSize=14]
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 24 HDFS Write: 92 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 7.225 seconds
##########################查询###########################################
hive> select * from t_bucket;
OK
1
5
9
12
18
1
5
9
12
18
Time taken: 0.171 seconds, Fetched: 10 row(s)
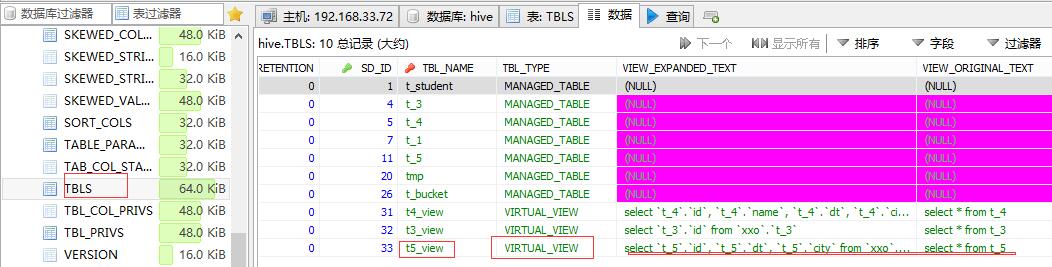
视图
- Hive 中,也有视图的概念,那我们都知道视图实际上是一张虚拟的表,是对数据的逻辑表示,只是一种显示的方式,主要的作用呢:
- 视图能够简化用户的操作
- 视图使用户能以多钟角度看待同一数据
- 视图对重构数据库提供了一定程度的逻辑独立性
- 视图能够对机密数据提供安全保护
- 适当的利用视图可以更清晰的表达查询
- 示例:
创建视图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
################创建视图###############################
hive> create view t5_view as select * from t_5;
OK
Time taken: 0.184 seconds
################查看数据##############################
hive> select * from t5_view;
OK
7 2015-05-30 bj
5 2015-05-30 cq
9 2015-05-30 hz
1 2015-05-30 wz
2 2015-05-30 yy
1 2016-05-28 cq
2 2016-05-28 cq
3 2016-05-28 cq
4 2016-05-28 cq
5 2016-05-28 cq
Time taken: 0.228 seconds, Fetched: 10 row(s)查看hdfs

查看元数据