
Hadoop--HDFS之DataNode
HDFS DataNode,提供真实文件数据的存储服务。上篇博客HDFS NameNode 讲的是HDFS元数据,本篇主要讲解HDFS存储的真实数据。这些真实数据重点由两个部分组成,一、Block块(数据存储单元),二、文件备份数,掌握Block块信息,副本数的设置。
Block块
- 文件块(block):最基本的存储单位。
- 对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block;
- HDFS,默认Block大小是128MB(2.0版本),以一个256MB文件,共有256/128=2个Block;
- HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
- NameNode和Block块关系
首先上传test.txt文件
1
2
3
4[root@xxo07 test]# ll -h ##大小4KB,33字节
total 4.0K
-rw-r--r--. 1 root root 33 Jun 26 20:04 test.txt
[root@xxo07 test]# hdfs dfs -put test.txt /in/test/查看详细信息,可以看见blkck ID:1073742177

导出fsimage文件(具体怎么导出,查看),blkck ID:1073742177

- Block数据信息
NameNode数据目录
1
2
3
4<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop_repo/name</value>
</property>查看我们上面的test文件block块数据信息
${dfs.namenode.name.dir}/current/下,blkck ID:1073742177
查看具体信息,可以发现是我们之前的文本信息,所以block块其实存放了原数据,没有任何序列化压缩等操作。
1
2
3
4[root@xxo07 subdir1]# more blk_1073742177 |more
hello world
xxo
xiaoxiaomo blog
Replication
- 设置副本的三种方式:
多复本,默认是三个,可以通过配置文件
hdfs-site.xml设置,我这里默认设置了一个副本(对已经上传了的文件不生效):1
2
3
4<property>
<name>dfs.replication</name>
<value>1</value>
</property>可以在上传文件时指定副本数(这是使用了-D去从新修改了参数):
hadoop dfs -D dfs.replication=2 -put test.txt /in
- 通过命令来更改已经上传的文件的副本数(这里把副本数修改为2):
[root@xxo07 hadoop]# hadoop fs -setrep -R 2 /in/test
Replication 2 set: /in/test/test.txt
注意:如果你只有1个datanode,却指定副本数为2,是不会生效的,因为每个datanode上只能存放一个副本(这样就会提示丢失了一个副本)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18[root@xxo07 hadoop]# hadoop fsck /in/test/test.txt
......
Status: HEALTHY
Total size: 33 B
Total dirs: 0
Total files: 1
Total symlinks: 0
Total blocks (validated): 1 (avg. block size 33 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 1 (100.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 1
Average block replication: 1.0
Corrupt blocks: 0
Missing replicas: 1 (50.0 %) ##丢失50%,因为我只有一个namenode,设置了2个副本,就会报告有丢失
Number of data-nodes: 1
Number of racks: 1通过命令:
hadoop fsck查看具体信息
如果某个NameNode节点挂掉
首先在副本机制下是没有什么问题的,如果节点没有全部挂掉,如果后期我们修复了机器,副本这么办呢?
下面来模拟一下:
2.1. 有节点xxo04(NameNode|DataNode)、xxo05(DataNode)、xxo06(SecondaryNameNode|DataNode):
2.2. kill 掉xxo05,此时通过hdfs fsck或web界面是看不出效果的,如果执行了start-balancer.sh结果就出来了
Default replication factor: 3
Average block replication: 2.0
Missing replicas: 1 (33.333332 %)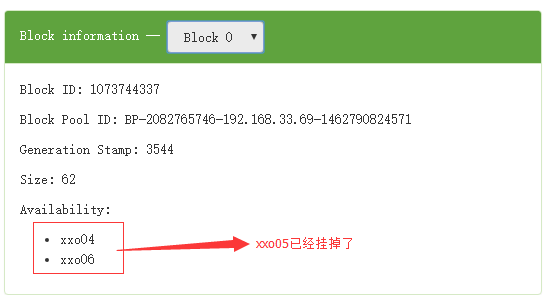
如果几点修好后,启动NameNode即可
hadoop-daemon.sh start datanode
副本策略
副本技术
副本技术即分布式数据复制技术,是分布式计算的一个重要组成部分。该技术允许数据在多个服务器端共享,一个本地服务器可以存取不同物理地点的远程服务器上的数据,也可以使所有的服务器均持有数据的拷贝。副本技术优点:
- 提高系统可靠性:系统不可避免的会产生故障和错误,拥有多个副本的文件系统不会导致无法访问的情况,从而提高了系统的可用性。另外,系统可以通过其他完好的副本对发生错误的副本进行修复,从而提高了系统的容错性。
- 负载均衡:副本可以对系统的负载量进行扩展。多个副本存放在不同的服务器上,可有效的分担工作量,从而将较大的工作量有效的分布在不同的站点上。
- 提高访问效率:将副本创建在访问频度较大的区域,即副本在访问节点的附近,相应减小了其通信开销,从而提高了整体的访问效率。
- 副本放置策略
- 块副本存放位置的选择严重影响 HDFS 的可靠性和性能。HDFS 采用机架敏感(rack awareness)的副本存放策略来提高数据的可靠性、可用性和网络带宽的利用率。
- HDFS 副本放置策略,例如副本数为3:
2.1. 将第一个副本放在本地节点;
2.2. 将第二个副本放到本地机架上的另外一个节点;
2.3. 将第三个副本放到不同机架上的节点。 - 这种方式减少了机架间的写流量,从而提高了写的性能。机架故障的几率远小于节点故障。这种方式并不影响数据可靠性和可用性的限制,并且它确实减少了读操作的网络聚合带宽,因为文件块仅存在两个不同的机架,而不是三个。文件的副本不是均匀地分布在机架当中,1/3 副本在同一个节点上,1/3 副本在同一个机架上,另外 1/3 副本均匀地分布在其他机架上。这种方式提高了写的性能,并且不影响数据的可靠性和读性能。