
Spark Streaming--应用与实战(三)
第一篇介绍了项目背景,为什么需要对架构进行一些改造,以及为啥要引入SparkStreaming,第二篇就是一些具体的方法实现,
第三篇,该篇主要在代码运行起来的情况下来看一下任务的运行情况主要是streaming的监控界面,以及我们怎么去通过监控界面发现问题和解决问题。
监控
- 官网中指出,spark中专门为SparkStreaming程序的监控设置了额外的途径,当使用StreamingContext时,在WEB UI中会出现一个”Streaming”的选项卡,

- 在此选项卡内,统计的内容展示如下:
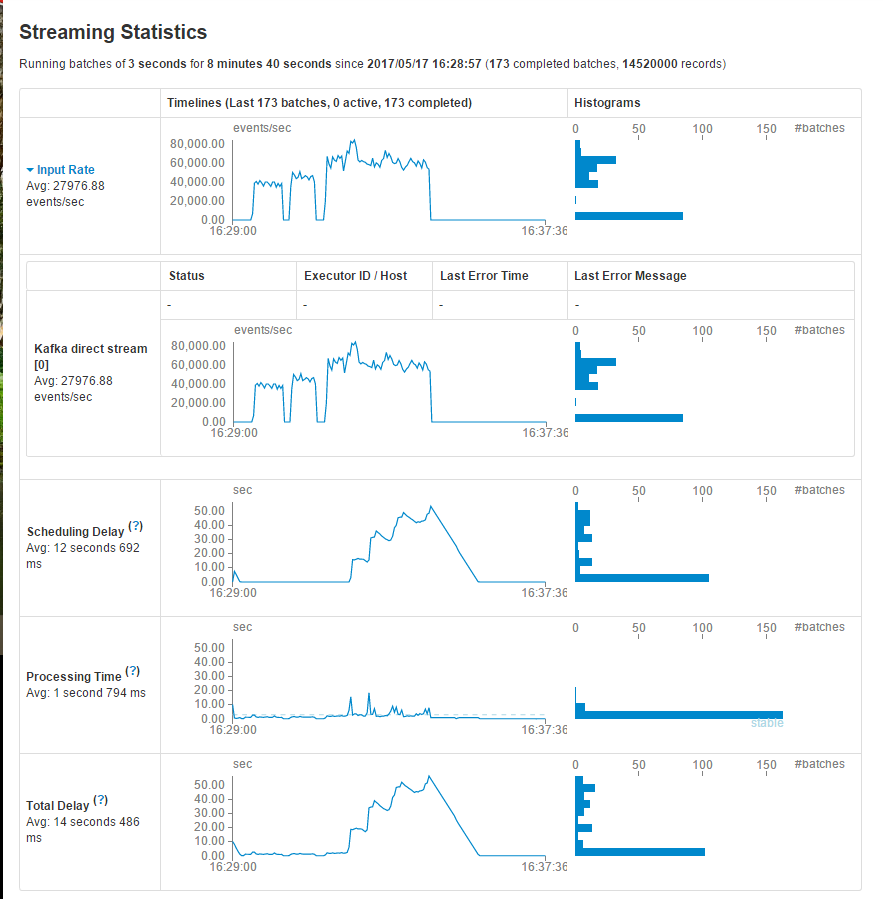
Spark streaming 处理速度为3s一次,每次1000条
Kafka product 每秒1000条数据, 与上面spark consumer消费者恰好相等。结果:数据量大导致积压,这个过程中active Batches会越变越大
因为忽略了实际的Processing time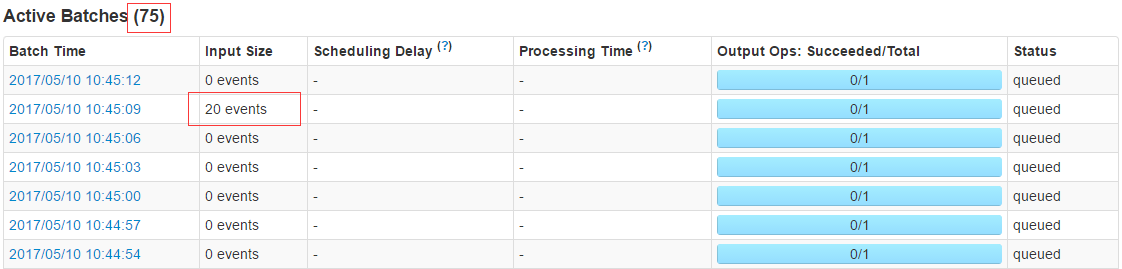


这其中包括接受的记录数量,每一个batch内处理的记录数,处理时间,以及总共消耗的时间。
在上述参数之中最重要的两个参数分别是Porcessing Time 以及 Scheduling Delay
Porcessing Time 用来统计每个batch内处理数据所消费的时间
Scheduling Delay 用来统计在等待被处理所消费的时间
如果PT比SD大,或者SD持续上升,这就表明此系统不能对产生的数据实时响应,换句话来说就是,出现了处理时延,每个batch time 内的处理速度小于数据的产生速度。
在这种情况下,读者需要想法减少数据的处理速度,即需要提升处理效率。
问题发现
在我做压测的时候, Spark streaming 处理速度为3s一次,每次1000条
Kafka product 每秒1000条数据, 与上面spark consumer消费者恰好相等。于是就会数据量大导致积压,这个过程中active Batches会越变越大
最后发现了一个问题

当压测峰值过后Input Size=0 events,时间任然不减,奇怪!

- 查看摸个具体stage:

从图中, 我们可以看到Spark总共调度分发了两批次task set, 每个task set的处理(含序列化和压缩之类的工作)都不超过100毫秒,
那么该Stage何来消耗4s呢? 慢着, 貌似这两批次的task set分发的时间相隔得有点长啊, 隔了4秒左右. 为什么会隔这么就才调度一次呢?
此处要引入一个配置项”spark.locality.wait”, (默认等待3s)
它配置了本地化调度降级所需要的时间. 这里概要补充下Spark本地化调度的知识, Spark的task一般都会分发到它所需数据的那个节点, 这称之为”NODE_LOCAL”,
但在资源不足的情况下, 数据所在节点未必有资源处理task, 因此Spark在等待了” spark.locality.wait”所配置的时间长度后, 会退而求其次, 分发到数据所在节点的同一个机架的其它节点上, 这是”RACK_LOCAL”,
当然, 也有更惨的, 就是再等了一段” spark.locality.wait”的时间长度后, 干脆随便找一台机器去跑task, 这就是”ANY”策略了.

官网解释:How long to wait to launch a data-local task before giving up and launching it on a less-local node. The same wait will be used to step through multiple locality levels (process-local, node-local, rack-local and then any). It is also possible to customize the waiting time for each level by setting spark.locality.wait.node, etc. You should increase this setting if your tasks are long and see poor locality, but the default usually works well.
来源: https://github.com/apache/spark/blob/66636ef0b046e5d1f340c3b8153d7213fa9d19c7/docs/configuration.md
而从上例看到, 即使用最差的”ANY”策略进行调度, task set的处理也只是花了100毫秒, 因此, 没必要非得为了”NODE_LOCAL”策略的生效而去等待那么长的时间, 特别是在流计算这种场景上. 所以把” spark.locality.wait”果断调小, 从1秒到500毫秒, 最后干脆调到100毫秒算了.
spark-submit –master yarn-client –conf spark.driver.memory=256m –class com.KafkaDataStream –num-executors 1 –executor-memory 256m –executor-cores 2 –conf spark.locality.wait=100ms hspark-1.0.jar
调了之后的处理时间为0.7s:
具体耗时如下