
Spark Streaming--应用与实战(四)
对项目做压测与相关的优化,主要从内存(executor-memory和driver-memory)、num-executors、executor-cores,以及代码层面做一些测试和改造。
压测
spark-submit –master yarn-client –conf spark.driver.memory=256m –class com.xiaoxiaomo.KafkaDataStream –num-executors 1 –executor-memory 256m –executor-cores 2 –conf spark.locality.wait=100ms hspark.jar 3 1000
Spark streaming 处理速度为3s一次,每次1000条
Kafka product 每秒1000条数据, 与上面spark consumer消费者恰好相等。结果:数据量大导致积压,这个过程中active Batches会越变越大.
- 调整Kafka product 每秒600条数据,存在积压,但已经不严重

- 调整Kafka product 每秒500条数据,为消费者50%,测试结果显示正常,等待时间很稳定
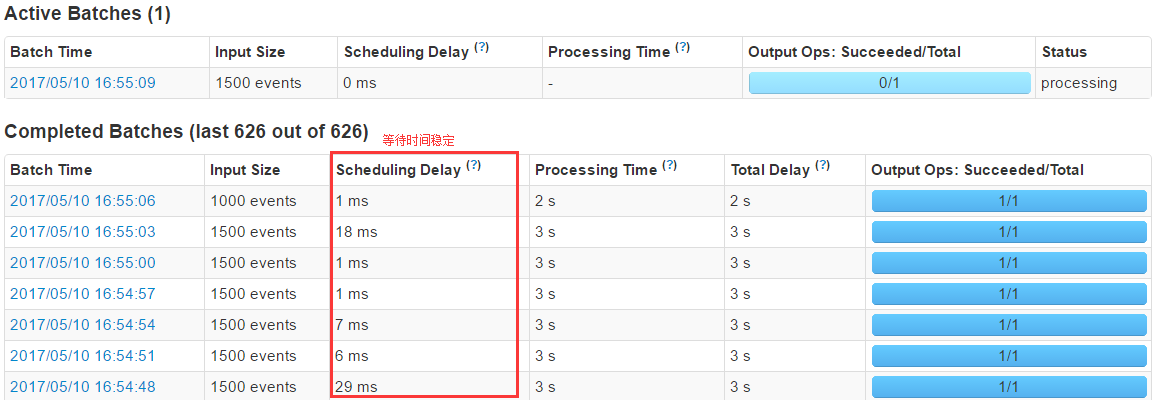
但是。此时每秒吞吐量为500 显然不够
- 通过调整间歇实际等,发现并没有变化
spark-submit –master yarn-client –conf spark.driver.memory=256m –class com.xiaoxiaomo.KafkaDataStream –num-executors 1 –executor-memory 256m –executor-cores 2 –conf spark.locality.wait=100ms hspark.jar 2 2000 Spark streaming 处理速度为2s一次,每次2000条
Kafka product 每秒500条数据,可以看见没有在指定时间内消费完数据,照成数据积压,并发下降了
分析原因
- 分析原因,发现大部分耗时都在处理数据这样一阶段,如下图所示

调整参数
调整 executor-cores
–executor-cores 2 并发上升至700/s
–executor-cores 3 并发上升至750/s
调整executor内存,并发没有增长,无效
–executor-memory 512m
–conf spark.yarn.executor.memoryOverhead=512调整am内存,并发没有增长,无效
–am-memory 512m
–conf spark.yarn.am.memoryOverhead=512
代码调整
发现现在主要还是在处理数据的时候消耗时间一直没有减少,而处理数据查看后发现是一条一条的往hbase里面插入的,修改为批量插入,重新构建了json.性能猛增!! 修改前的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37/**
*
* 插入数据到 HBase
*
* 参数( tableName , json ) ):
*
* Json格式:
* {
* "rowKey": "00000-0",
* "family:qualifier": "value",
* "family:qualifier": "value",
* ......
* }
*
* @param data
* @return
*/
def insert(data: (String, String)): Boolean = {
val t: HTable = getTable(data._1) //HTable
try {
val map: mutable.HashMap[String, Object] = JsonUtils.json2Map(data._2)
val rowKey: Array[Byte] = String.valueOf(map.get("rowKey")).getBytes //rowKey
val put = new Put(rowKey)
for ((k, v) <- map) {
val keys: Array[String] = k.split(":")
if (keys.length == 2){
put.addColumn(keys(0).getBytes, keys(1).getBytes, String.valueOf(v).getBytes)
}
}
Try(t.put(put)).getOrElse(t.close())
true
} catch {
case e: Exception =>
e.printStackTrace()
false
}
}修改后的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//数据操作
messages.foreachRDD(rdd => {
val offsetsList: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
//data 处理
rdd.foreachPartition(partitionRecords => {
//TaskContext 上下文
val offsetRange: OffsetRange = offsetsList(TaskContext.get.partitionId)
logger.debug(s"${offsetRange.topic} ${offsetRange.partition} ${offsetRange.fromOffset} ${offsetRange.untilOffset}")
//TopicAndPartition 主构造参数第一个是topic,第二个是Kafka partition id
val topicAndPartition = TopicAndPartition(offsetRange.topic, offsetRange.partition)
val either = kc.setConsumerOffsets(groupName, Map((topicAndPartition, offsetRange.untilOffset))) //是
if (either.isLeft) {
logger.info(s"Error updating the offset to Kafka cluster: ${either.left.get}")
}
/** 解析PartitionRecords数据 */
if (offsetRange.topic != null) {
HBaseDao.insert(offsetRange.topic, partitionRecords)
}
})
})插入数据到 HBase
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51/**
*
* 插入数据到 HBase
*
* 参数( tableName , [( tableName , json )] ):
*
* Json格式:
* {
* "r": "00000-0",
* "f": "family",
* "q": [
* "qualifier",
* "qualifier"
* ...
* ],
* "v": [
* "value",
* "value"
* ...
* ],
* }
*
* @return
*/
def insert(tableName: String, array: Iterator[(String, String)]): Boolean = {
try {
/** 操作数据表 && 操作索引表 */
val t: HTable = getTable(tableName) //HTable
val puts: util.ArrayList[Put] = new util.ArrayList[Put]()
/** 遍历Json数组 */
array.foreach(json => {
val jsonObj: JSONObject = JSON.parseObject(json._2)
val rowKey: Array[Byte] = jsonObj.getString("r").getBytes
val family: Array[Byte] = jsonObj.getString("f").getBytes
val qualifiers: JSONArray = jsonObj.getJSONArray("q")
val values: JSONArray = jsonObj.getJSONArray("v")
val put = new Put(rowKey)
for (i <- 0 until qualifiers.size()) {
put.addColumn(family, qualifiers.getString(i).getBytes, values.getString(i).getBytes)
}
puts.add(put)
})
Try(t.put(puts)).getOrElse(t.close())
true
} catch {
case e: Exception =>
e.printStackTrace()
logger.error(s"insert ${tableName} error ", e)
false
}
}
运行
- 刚测试时给它相对很小的内存跑一跑
1
2
3
4
5
6
7[root@xiaoxiaomo.com ~]# /opt/cloudera/parcels/CDH/bin/spark-submit \
--master yarn-client --num-executors 1 \
--driver-memory 256m --conf spark.yarn.driver.memoryOverhead=256 \
--conf spark.yarn.am.memory=256m --conf spark.yarn.am.memoryOverhead=256 \
--executor-memory 256m --conf spark.yarn.executor.memoryOverhead=256 \
--executor-cores 1 \
--class com.creditease.streaming.KafkaDataStream hspark-1.0.jar 1 3 30000
- 五六万的插入没什么压力,但是到10万的时候,就有些卡顿了!!


- 当然是需要增大内存的,修改配置,都增加一倍
1
2
3
4
5
6
7[root@xiaoxiaomo.com ~]# /opt/cloudera/parcels/CDH/bin/spark-submit \
--master yarn-client --num-executors 2 \
--driver-memory 512m --conf spark.yarn.driver.memoryOverhead=512 \
--conf spark.yarn.am.memory=512m --conf spark.yarn.am.memoryOverhead=512 \
--executor-memory 512m --conf spark.yarn.executor.memoryOverhead=512 \
--executor-cores 1 \
--class com.creditease.streaming.KafkaDataStream hspark-1.0.jar 1 3 30000

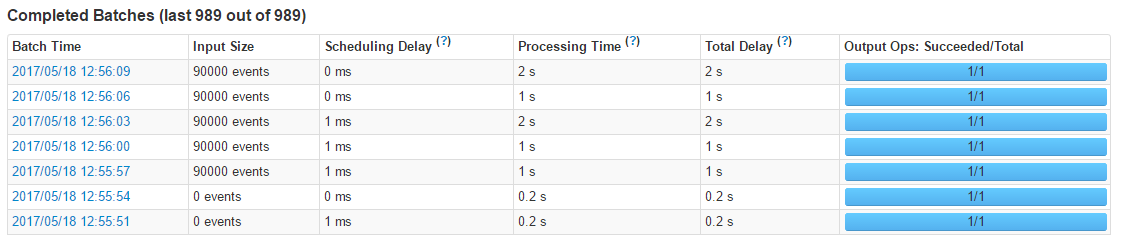
- 查看插入数据量,能看到修改后插入数据10万是没有什么压力的

当我们再继续加大压力测试的时候,性能下降
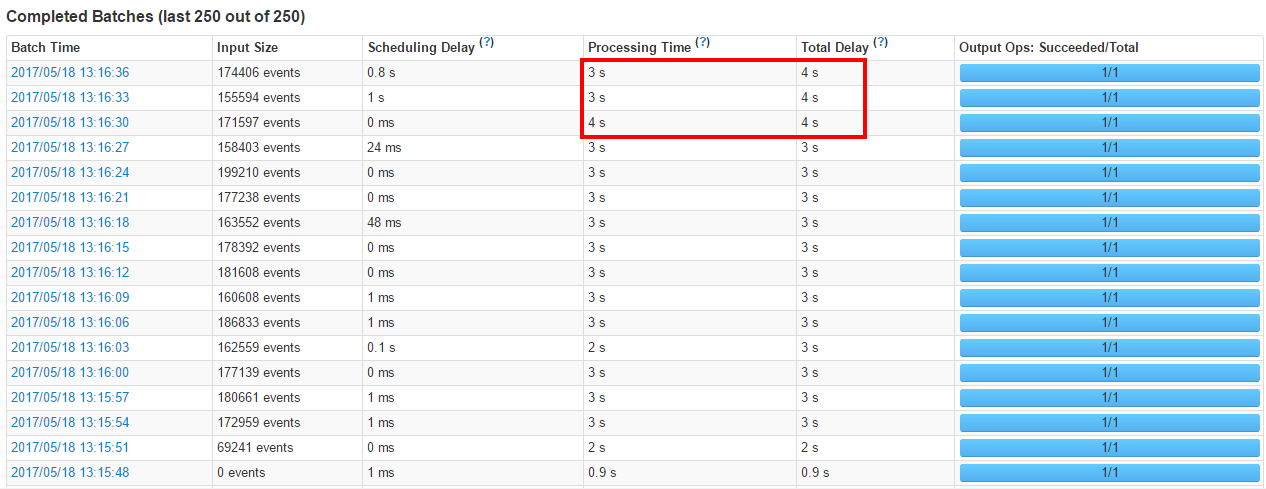
查看统计信息
