



这里主要梳理一下大数据常用的监控组件的组合使用,jmxtrans+influxdb+Grafana。jmxtrans用于收集服务的jmx信息(通过配置json文件),然后入库到influxDB。
通过配置Grafana,把influxDB里面的数据通过web展示出来。
我这里主要做一些简单的安装,然后以HBase为例做收集存储展示,更多详细的内容,会在后面的内容分享。
influxDB安装
下载地址:https://portal.influxdata.com/downloads/#influxdb
- 我这里通过wget下载1.7.5的版本
- wget https://dl.influxdata.com/influxdb/releases/influxdb-1.7.5.x86_64.rpm
安装
- sudo yum localinstall influxdb-1.7.5.x86_64.rpm
启动
1
2
3[root@fetch-slave2 ~]# service influxdb start
Starting influxdb...
influxdb process was started [ OK ]
- 讨论ConcurrentHashMap之前,我们首先了解一下java提供了那些不同层面上的线程安全的支持。了解一下大概的分类,然后在具体看ConcurrentHashMap的细节,分类如下:
- 同步包装器(java.util.Collections工具类提供的包装方法),如Collections.synchronizedMap等,但是它们都是利用非常粗粒度的同步方式,在高并发情况下,性能比较低下。
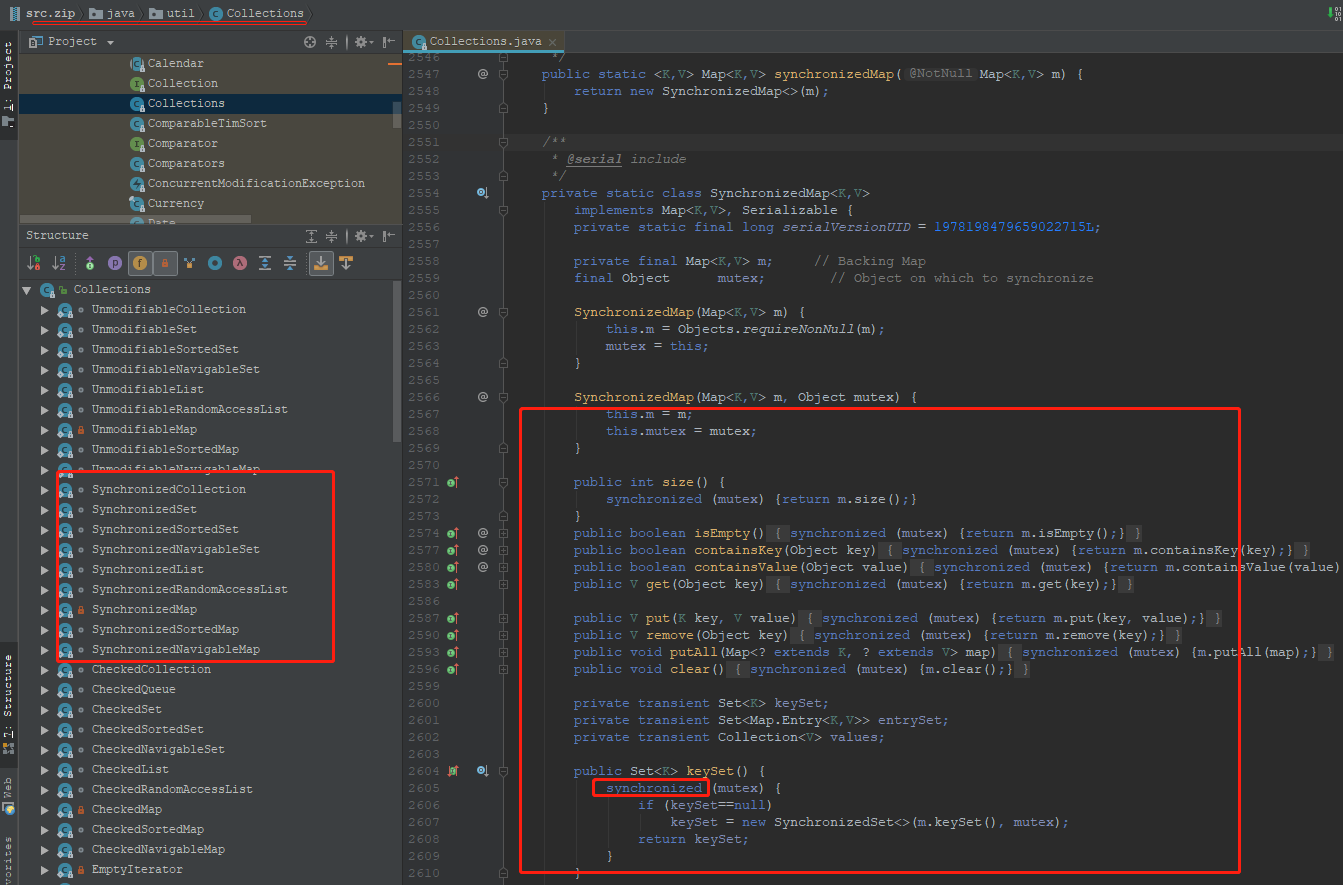

线程不安全?首先看看线程的工作原理,jvm有一个main memory,而每个线程有自己的working memory,一个线程对一个变量进行操作时,都要在自己的working memory里面建立一个copy,操作完之后再写入main memory。多个线程同时操作同一个变量(variable),就可能会出现不可预知的结果,即线程不安全。
而用synchronized(同步)的关键是建立一个monitor,这个monitor可以是要修改的变量,也可以是其他你认为合适的object比如method,然后通过给这个monitor加锁来实现线程安全,每个线程在获得这个锁之后,要执行完 load到working memory -> use&assign -> store到main memory的过程,才会释放它得到的锁。这样就实现了所谓的线程安全。
总结:synchronized 使一段代码同时只能有一个线程来操作,其实就是给对象加了锁,来实现线程安全。

当前网速较慢或者你使用的浏览器不支持博客特定功能,请尝试刷新或换用Chrome、Firefox等现代浏览器