
Java--NIO之缓冲区进阶
上一篇http://blog.xiaoxiaomo.com/2016/04/16/Java-NIO之缓冲区/讲了基本的缓冲区概念、属性以及部分操作。本片博客,主要讲解缓冲区的创建、复制和字节缓冲区。
缓冲区的创建
对于这一讨论,我们将以 CharBuffer 类为例,但是对于其它六种主要的缓冲区类也是适用的:IntBuffer,DoubleBuffer,ShortBuffer,LongBuffer,FloatBuffer,和 ByteBuffer。下面是创建一个缓冲区的关键函数,对所有的缓冲区类通用(要按照需要替换类名):
1 | public abstract class CharBuffer |
新的缓冲区是由分配或包装操作创建的。
- 分配操作:创建一个缓冲区对象并分配一个私有的空间来储存容量大小的数据元素。
- 包装操作创建一个缓冲区对象但是不分配任何空间来储存数据元素。它使用您所提供的数组作为存储空间来储存缓冲区中的数据元素。
- 实例一
要分配一个容量为 100 个 char 变量的 Charbuffer:
CharBuffer charBuffer = CharBuffer.allocate (100);
这段代码隐含地从堆空间中分配了一个 char 型数组作为备份存储器来储存 100 个 char变量。
- 实例二
如果您想提供您自己的数组用做缓冲区的备份存储器,请调用 wrap()函数:
char [] myArray = new char [100];
CharBuffer charbuffer = CharBuffer.wrap (myArray);
这段代码构造了一个新的缓冲区对象,但数据元素会存在于数组中。这意味着通过调用put()函数造成的对缓冲区的改动会直接影响这个数组,而且对这个数组的任何改动也会对这个缓冲区对象可见。
带有 offset 和 length 作为参数的 wrap()函数版本则会构造一个按照您提供的 offset 和 length 参数值初始化位置和上界的缓冲区。如下:
CharBuffer charbuffer = CharBuffer.wrap (myArray, 12, 42);
创建了一个position值为12,limit值为54(12+42),容量为myArray.length的缓冲区。
- wrap方法使用一个现有的数组作为缓冲区备份。
其实缓冲区都需要这样一个真正存放数据的地方,我们可以看看allocate方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
//HeapByteBuffer
//用父类的构造函数来初始化。
//第一个参数:mark,-1表示undefined,
//第二个参数:position
//第三个参数:limit
//第四个参数:capacity,
//第五个参数:数组,
//第六个参数:数组的偏移。
HeapByteBuffer(int cap, int lim) {
super(-1, 0, lim, cap, new byte[cap], 0);
/*
hb = new byte[cap];
offset = 0;
*/
}
我们还应该看到一个函数,hasArray(),这说明并非所有的缓冲区都包含一个数组,那么什么样的缓冲区不包含数组呢?答案是直接缓冲区。通过allocate和wrap创建的缓冲区都是间接的,事实上缓冲区都必须又一个存放数据的地方。
- 如果是直接缓冲区,我们是不能获取到数组的,所以array方法不能在直接缓冲区中调用,否则抛出
UnsupportedOperationException异常。当然,如果是只读的缓冲区,我们也不能调用array方法或者是arrayOffset方法。 arrayOffset方法是返回作为备份数组的起始下标。这就说明,并非一个数组必须是所有元素都在缓冲区内,而是可以拆分的。但是这里还没讲到,所以,以上提到的缓冲区,如果使用arrayOffset方法,返回都是0.为了方便,我们的CharBuffer提供了几个方法:
1
2
3
4
5
6public abstract class CharBuffer
extends Buffer implements CharSequence, Comparable {
// This is a partial API listing
public static CharBuffer wrap (CharSequence csq) ;
public static CharBuffer wrap (CharSequence csq, int start, int end);
}
可以这样用,CharBuffer charBuffer = CharBuffer.wrap (“Hello World”);这对于字符集码和正则表达式处理都是很方便的。
复制缓冲区
这里的复制,仅仅是复制缓冲区,而不是数据。1
2
3
4
5
6
7public abstract class CharBuffer
extends Buffer implements CharSequence, Comparable {
// This is a partial API listing
public abstract CharBuffer duplicate( );
public abstract CharBuffer asReadOnlyBuffer( );
public abstract CharBuffer slice( );
}
- duplicate() 函数创建了一个与原始缓冲区相似的新缓冲区。两个缓冲区共享数据元素,拥有同样的容量,但每个缓冲区拥有各自的位置,上界和标记属性。对一个缓冲区内的数据元素所做的改变会反映在另外一个缓冲区上。这一
副本缓冲区具有与原始缓冲区同样的数据视图。如果原始的缓冲区为只读,或者为直接缓冲区,新的缓冲区将继承这些属性。1
2
3
4CharBuffer buffer = CharBuffer.allocate (8);
buffer.position (3).limit (6).mark( ).position (5);
CharBuffer dupeBuffer = buffer.duplicate( );
buffer.clear( );

asReadOnlyBuffer() 函数来生成一个只读的缓冲区视图。这与duplicate()相同,除了这个新的缓冲区不允许使用 put(),并且其 isReadOnly()函数将会返回true。对这一只读缓冲区的put()函数的调用尝试会导致抛出
ReadOnlyBufferException异常。slice() 创建一个从原始缓冲区的当前位置开始的新缓冲区,并且
其容量是原始缓冲区的剩余元素数量(limit-position)。这个新缓冲区与原始缓冲区共享一段数据元素子序列。分割出来的缓冲区也会继承只读和直接属性1
2
3CharBuffer buffer = CharBuffer.allocate (8);
buffer.position (3).limit (5);
CharBuffer sliceBuffer = buffer.slice( );

要创建一个映射到数组位置 12-20(9 个元素)的 buffer 对象,应使用下面的代码实现。1
2
3
4char [] myBuffer = new char [100];
CharBuffer cb = CharBuffer.wrap (myBuffer);
cb.position(12).limit(21);
CharBuffer sliced = cb.slice( );
字节缓冲区
字节顺序
非字节类型的基本类型,除了布尔型都是由组合在一起的几个字节组成的。这些数据类型及其大小:
每个基本数据类型都是以连续字节序列的形式存储在内存中。例如,32 位的 int 值0x037fb4c7(十进制的 58,700,999)有两种存储方式。
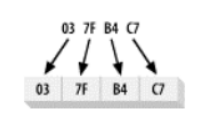

多字节数值被存储在内存中的方式一般被称为 endian-ness(字节顺序)。数字数值的最高字节——big end(大端),位于低位地址那么系统就是大端字节顺序,反则小端。字节顺序的问题甚至胜过CPU硬件设计。当Internet的设计者为互联各种类型的计算机而设计网际协议(IP)时,他们意识到了在具有不同内部字节顺序的系统间传递数值数据的问题。因此,
IP协议规定了使用大端的网络字节顺序概念。在 java.nio 中,字节顺序由 ByteOrder 类封装1
2
3
4
5
6
7package java.nio;
public final class ByteOrder {
public static final ByteOrder BIG_ENDIAN; //大端
public static final ByteOrder LITTLE_ENDIAN; //小端
public static ByteOrder nativeOrder();
public String toString();
}
如果您需要知道 JVM 运行的硬件平台的固有字节顺序,请调用静态类函数,nativeOrder()。它将返回两个已确定常量中的一个。
4 . 每个缓冲区类都具有一个能够通过调用 order()查询的当前字节顺序设定。1
2
3
4
5public abstract class CharBuffer extends Buffer
implements Comparable, CharSequence{
// This is a partial API listing
public final ByteOrder order( )
}
ByteOrder 返回两个常量之一。对于除了 ByteOrder 之外的其他缓冲区类,字节顺序是一个只读属性,并且可能根据缓冲区的建立方式而采用不同的值。
5 . ByteBuffer 类有所不同:默认字节顺序总是 ByteBuffer.BIG_ENDIAN,无论系统的固有字节顺序是什么。ByteBuffer 的字符顺序设定可以随时通过调用以 ByteOrder.BIG_ENDIAN 或ByteOrder.LITTL_ENDIAN 为参数的 order()函数来改变。1
2
3
4
5
6public abstract class ByteBuffer extends Buffer
implements Comparable{
// This is a partial API listing
public final ByteOrder order( )
public final ByteBuffer order (ByteOrder bo)
}
现在知道了字节顺序,那么字节缓冲区转换为其他缓冲区,也就清楚了。
比如,我们有一个4字节缓冲区 0x01 0x23 0x45 0x67
转换为一个IntBuffer,那么,根据字节顺序,如果是大端,直接就是 0x1234567
如果是小端顺序,那么读出来就是 0x67452301
注意:视图缓冲区一旦创建,字节顺序是不可改变的。视图缓冲区后面讲到
直接缓冲区
allocate和wrap创建的都是间接缓冲区。间接缓冲区,就是在操作系统和JVM之间其实有一层,我们如果对一个间接缓冲区使用,那么首先是要在操作系统层次创建一个临时缓冲区,然后copy过去,再操作,在删除临时缓冲区。这都很麻烦。通常有如下几步:1.创建一个临时的直接 ByteBuffer 对象。
2.将非直接缓冲区的内容复制到临时缓冲中
3.使用临时缓冲区执行低层次 I/O 操作。
4.临时缓冲区对象离开作用域,并最终成为被回收的无用数据。直接缓冲区时 I/O 的最佳选择,但可能比创建非直接缓冲区要花费更高的成本。直接缓冲区使用的内存是通过调用本地操作系统方面的代码分配的,绕过了标准 JVM 堆栈。建立和销毁直接缓冲区会明显比具有堆栈的缓冲区更加破费,这取决于主操作系统以及 JVM 实现。直接缓冲区的内存区域不受无用存储单元收集支配,因为它们位于标准 JVM 堆栈之外。
使用直接缓冲区或非直接缓冲区的性能权衡会因JVM,操作系统,以及代码设计而产生巨大差异。
使用 allocateDirect方法就可以获得直接缓冲区。
1
2
3public static ByteBuffer allocateDirect (int capacity)
public abstract boolean isDirect( );
//isDirect对于直接缓冲区的非字节视图缓冲区,也可能返回true
视图缓冲区
字节缓冲区是所有缓冲类型的基础。我们在通道中,网络中文件流中四处传递字节缓冲区。但是,一旦进入应用,我们就要通过视图缓冲区来解读具体的数据了。字节缓冲区提供了很多这样的API。1
2
3
4
5
6
7
8
9
10public abstract class ByteBuffer
extends Buffer implements Comparable {
// This is a partial API listing
public abstract CharBuffer asCharBuffer( );
public abstract ShortBuffer asShortBuffer( );
public abstract IntBuffer asIntBuffer( );
public abstract LongBuffer asLongBuffer( );
public abstract FloatBuffer asFloatBuffer( );
public abstract DoubleBuffer asDoubleBuffer( );
}
前面提到过从ByteBuffer到IntBuffer的转换。其实这种转换,是一种解释包装。
所以需要提供一个顺序,然后按照顺序和类型,转换成另外一种视图,而原始数据其实是不变的。
例如,我们可以这样;1
2
3ByteBuffer byteBuffer =
ByteBuffer.allocate(7).order(ByteOrder.BIG_ENDIAN);
CharBuffer charBuffer = byteBuffer.asCharBuffer();
注意,java中char是占两个字节的。我们的转换可以看下图:
新的charBuffer视图其实还是使用的原来的缓冲区的数据,只是这时的元素变成了2个字节的char了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import java.nio.Buffer;
import java.nio.ByteBuffer;
import java.nio.ByteOrder;
import java.nio.CharBuffer;
public class CharBufferView {
public static void print(Buffer buffer){
System.out.println("pos="+buffer.position()+", limit="+
buffer.limit() + ", capacity="+buffer.capacity()
+":'" + buffer.toString()+"'");
}
public static void main(String[] args)
throws Exception{
ByteBuffer byteBuffer = ByteBuffer.allocate(8).order(ByteOrder.BIG_ENDIAN);
CharBuffer charBuffer = byteBuffer.asCharBuffer();
byteBuffer.put(0,(byte)0);
byteBuffer.put(1,(byte)'H');
byteBuffer.put(2,(byte)0);
byteBuffer.put(3,(byte)'e');
byteBuffer.put(4,(byte)0);
byteBuffer.put(5,(byte)'l');
byteBuffer.put(6,(byte)0);
byteBuffer.put(7,(byte)'l');
byteBuffer.put(8,(byte)0);
byteBuffer.put(9,(byte)'o');
CharBufferView.print(byteBuffer);
CharBufferView.print(charBuffer);
}
}
- 结果:
pos=0, limit=10, capacity=10:’java.nio.HeapByteBuffer[pos=0 lim=10 cap=10]’
pos=0, limit=5, capacity=5:’Hello’
可以看到,转换为视图后,limit和capacity都变了。
数据元素视图
上面的视图使用了一个视图类来转换。在ByteBuffer中,我们可以直接获取不同视图的元素。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public abstract class ByteBuffer
extends Buffer implements Comparable {
public abstract char getChar( );
public abstract char getChar (int index);
public abstract short getShort( );
public abstract short getShort (int index);
public abstract int getInt( );
public abstract int getInt (int index);
public abstract long getLong( );
public abstract long getLong (int index);
public abstract float getFloat( );
public abstract float getFloat (int index);
public abstract double getDouble( );
public abstract double getDouble (int index);
public abstract ByteBuffer putChar (char value);
public abstract ByteBuffer putChar (int index, char value);
public abstract ByteBuffer putShort (short value);
public abstract ByteBuffer putShort (int index, short value);
public abstract ByteBuffer putInt (int value);
public abstract ByteBuffer putInt (int index, int value);
public abstract ByteBuffer putLong (long value);
public abstract ByteBuffer putLong (int index, long value);
public abstract ByteBuffer putFloat (float value);
public abstract ByteBuffer putFloat (int index, float value);
public abstract ByteBuffer putDouble (double value);
public abstract ByteBuffer putDouble (int index, double value);
}
这些操作一看便知。前面也提过其实就是根据大端小端的字节顺序,和这些数据类型的长度来组织数据。这里需要注意的是:如果get或者是put时,数据不足,或者空间不够,都会发生异常。如果不是用putXX的方法,直接getXX,那么可能产生意想不到的问题。
无符号数存取
对于java来说,没有无符号数处理(除了char)。为此,书中给出一个程序,用来处理无符号数缓冲区。
其基本原理是,使用比要存取的数据类型更大的数据类型来存放这个数,同时使用与运算强制设置符号位为0,剩余的位就可以作为数据而不是符号位了。
1 | public class Unsigned |
内存映射缓冲区
1 | 映射缓冲区是与文件存储的数据元素关联的字节缓冲区,它通过内存映射来访问。映射缓 |