
Idea/Eclipse--Windows下调试Hadoop
我想大家对于java的单元测试junit都很熟悉了吧,这里我就不介绍了。下面主要介绍Hadoop的测试(mrunit)的使用,以及在windows下我们在开发工具(Idea/Eclipse)本地调试和集群模式。本博客项目结构如下:

MRunit
就直接进入主题吧,对于mrunit的使用,首先我们加入依赖包:
mrunit和junit依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<!-- mrunit -->
<dependency>
<groupId>org.apache.mrunit</groupId>
<artifactId>mrunit</artifactId>
<version>1.0.0</version>
<classifier>hadoop2</classifier>
<scope>test</scope>
</dependency>
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>一个简单的WordCountApp用于统计单词的MapReduce
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98package com.xxo.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.Logger;
import java.io.IOException;
/**
* 通过MapReduce统计单词次数
* Created by xiaoxiaomo on 2016/5/20.
*/
public class WordCountApp {
private static Logger logger = Logger.getLogger( WordCountApp.class ) ;
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance( conf,WordCountApp.class.getSimpleName()) ;
job.setJarByClass(WordCountApp.class);
//1. 数据来源
FileInputFormat.setInputPaths(job, args[0]);
FileInputFormat.setInputDirRecursive(job, true); //递归
//2. 使用Mapper计算
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//3. 使用Reducer合并计算
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//4. 数据写入
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//5. 执行
job.waitForCompletion(true) ;
}
/**
* 自定义的Map 需要继承Mapper
*/
public static class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> {
Text k2 = new Text() ;
LongWritable v2 = new LongWritable();
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1. 获取行信息
String line = value.toString();
logger.info("该行数据:" + line);
//2. 获取行的所用单词
String[] words = line.split("\t");
for (String word : words) {
logger.info( " 设置的键和值:" + word + " - 1");
k2.set(word.getBytes()) ; //设置键
v2.set(1); //设置值
context.write(k2,v2);
}
}
}
/**
* 自定义的Reduce 需要继承Reducer
*/
public static class WordCountReducer extends Reducer<Text , LongWritable ,Text ,LongWritable>{
//K1 = K3
LongWritable v3 = new LongWritable() ;
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0 ;
logger.info("Reduce 键key:" + key);
for (LongWritable value : values) {
logger.info(" 设置的值:" + value);
sum +=value.get() ;
}
v3.set(sum);
context.write( key , v3 );
}
}
}下面我们就来写一个简单的mrunit吧,代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79import com.google.common.collect.Lists;
import com.xxo.mr.WordCountApp;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.apache.hadoop.mrunit.mapreduce.ReduceDriver;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.ArrayList;
/**
* mrunit Test
* Created by xiaoxiaomo on 2016/5/20.
*/
public class WordCountAppTest {
//单词统计Mapper
private WordCountApp.WordCountMapper wordCountMapper;
//单词统计Reducer
private WordCountApp.WordCountReducer wordCountReducer;
//Mapper和Reducer的Driver
private MapDriver<LongWritable, Text, Text, LongWritable> mapDriver;
private ReduceDriver<Text, LongWritable, Text, LongWritable> reduceDriver;
//private MapReduceDriver mrDriver;
public void before(){
this.wordCountMapper = new WordCountApp.WordCountMapper();
this.wordCountReducer = new WordCountApp.WordCountReducer();
this.mapDriver = MapDriver.newMapDriver(wordCountMapper);
this.reduceDriver = ReduceDriver.newReduceDriver(wordCountReducer);
//也可以这样写:同时测试map和reduce
//this.mrDriver = MapReduceDriver.newMapReduceDriver(wordCountMapper, wordCountReducer);
}
public void testMap() throws IOException {
//设置输入数据
this.mapDriver.addInput(new LongWritable(0), new Text("blog\txiaoxiaomo"));
this.mapDriver.addInput(new LongWritable(0), new Text("xxo\tblog"));
this.mapDriver.addOutput(new Text("blog"), new LongWritable(1));
this.mapDriver.addOutput(new Text("xiaoxiaomo"), new LongWritable(1));
this.mapDriver.addOutput(new Text("xxo"), new LongWritable(1));
this.mapDriver.addOutput(new Text("blog"), new LongWritable(1));
this.mapDriver.runTest();
}
public void testReduce() throws IOException{
ArrayList<LongWritable> values = Lists.newArrayList(new LongWritable(1), new LongWritable(2));
this.reduceDriver.addInput(new Text("xiaoxiaomo"), values);
this.reduceDriver.addInput(new Text("blog"), values);
this.reduceDriver.run();
}
}
///////运行结果
///////Mapper
//2016-05-21 01:06:01 WordCountApp [INFO] 该行数据:blog xiaoxiaomo
//2016-05-21 01:06:01 WordCountApp [INFO] 设置的键和值:blog - 1
//2016-05-21 01:06:02 WordCountApp [INFO] 设置的键和值:xiaoxiaomo - 1
//2016-05-21 01:06:02 WordCountApp [INFO] 该行数据:xxo blog
//2016-05-21 01:06:02 WordCountApp [INFO] 设置的键和值:xxo - 1
//2016-05-21 01:06:02 WordCountApp [INFO] 设置的键和值:blog - 1
///////Reduce
//2016-05-21 01:07:53 WordCountApp [INFO] Reduce 键key:xiaoxiaomo
//2016-05-21 01:07:53 WordCountApp [INFO] 设置的值:1
//2016-05-21 01:07:53 WordCountApp [INFO] 设置的值:2
//2016-05-21 01:07:53 WordCountApp [INFO] Reduce 键key:blog
//2016-05-21 01:07:53 WordCountApp [INFO] 设置的值:1
//2016-05-21 01:07:53 WordCountApp [INFO] 设置的值:2
调试hadoop
准备
下载后解压到目录(博主解压到:D:\dev\hadoop\bin\下面)bin下面包含文件
1
2
3
4
5
6
7hadoop.dll
hadoop.exp
hadoop.lib
hadoop.pdb
libwinutils.lib
winutils.exe
winutils.pdb配置环境变量(配置好后记得重启你的IDE工具)
HADOOP_HOME=D:\dev\hadoopPATH=%HADOOP_HOME%\bin
IDEA 调试hadoop
本地调试
一、点击Idea 右上角配置运行环境

二、点击“+”号,添加配置

三、设置运行环境变量和参数
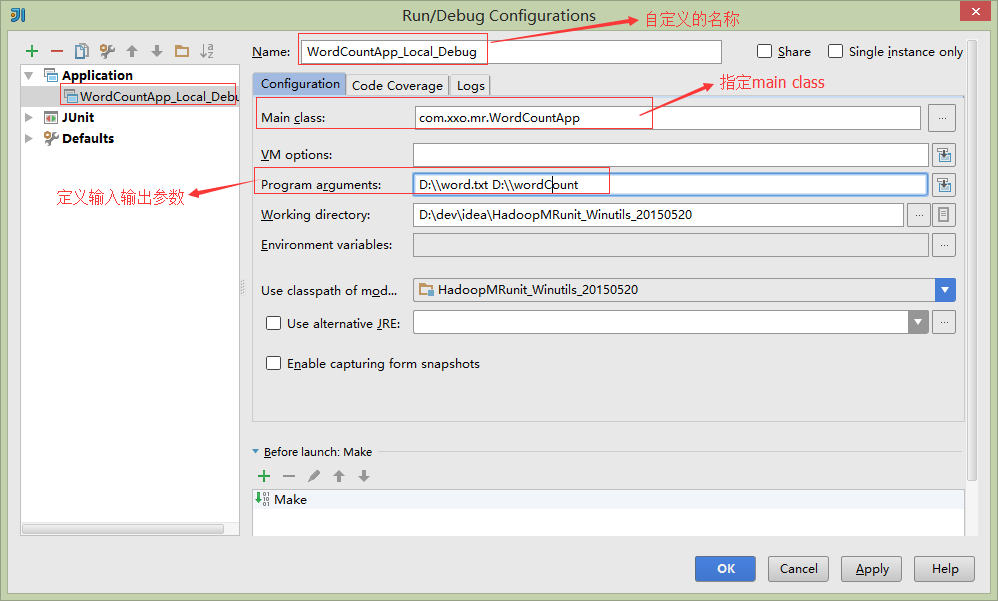
四、运行结果如下:

远程模式
集群模式是本地向集群提交作业。
将集群中的配置文件core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml文件放在项目的resources目录下
在mapred-site.xml中添加如下内容:
1
2
3
4
5
6
7
8<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
<property>
<name>HadoopMRunit_Winutils_20150520-1.0-SNAPSHOT-jar-with-dependencies.jar</name>
<value>D:\\dev\\idea\\HadoopMRunit_Winutils_20150520\\target\\HadoopMRunit_Winutils_20150520-1.0-SNAPSHOT-jar-with-dependencies.jar</value>
</property>配置运行环境

Maven 打包 :
mvn clean install- 运行即可
eclipse 调试hadoop
- 在eclipse中调试hadoop基本和idea一样的,只是设置运行参数的位置不同而已,就不详细讲解了,如图:

常见错误
一、org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
302016-05-21 09:39:44 JobSubmitter [INFO] Cleaning up the staging area file:/tmp/hadoop-Jason/mapred/staging/Jason477647952/.staging/job_local477647952_0001
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:557)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977)
at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:187)
at org.apache.hadoop.util.DiskChecker.checkDirAccess(DiskChecker.java:174)
at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:108)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:285)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:344)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:150)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:131)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:115)
at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:131)
at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:163)
at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:731)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:536)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1314)
at com.xxo.mr.WordCount.main(WordCount.java:73)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:140)分析:从错误信息和源码发现,权限不足

解决办法(两种办法):
- 以管理员的身份启动ide开发工具。
- 还有一种办法就是重写源代码,如下图所示:

二、Permission denied: user=Jason, access=EXECUTE, inode=”/history”:root:supergroup:drwxrwx—
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
532016-05-21 10:53:18 JobSubmitter [INFO] Cleaning up the staging area /history/Jason/.staging/job_1463827152309_0001
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=Jason, access=EXECUTE, inode="/history":root:supergroup:drwxrwx---
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkFsPermission(FSPermissionChecker.java:271)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:257)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:208)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:171)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:6512)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:6494)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOwner(FSNamesystem.java:6413)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.setPermissionInt(FSNamesystem.java:1719)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.setPermission(FSNamesystem.java:1699)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.setPermission(NameNodeRpcServer.java:614)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.setPermission(ClientNamenodeProtocolServerSideTranslatorPB.java:443)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:962)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2039)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2035)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2033)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:525)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:106)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:73)
at org.apache.hadoop.hdfs.DFSClient.setPermission(DFSClient.java:2326)
at org.apache.hadoop.hdfs.DistributedFileSystem$24.doCall(DistributedFileSystem.java:1286)
at org.apache.hadoop.hdfs.DistributedFileSystem$24.doCall(DistributedFileSystem.java:1282)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.setPermission(DistributedFileSystem.java:1282)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:599)
at org.apache.hadoop.mapreduce.JobSubmitter.copyAndConfigureFiles(JobSubmitter.java:182)
at org.apache.hadoop.mapreduce.JobSubmitter.copyAndConfigureFiles(JobSubmitter.java:390)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:483)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1314)
at com.xxo.mr.WordCountApp.main(WordCountApp.java:47)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:140)
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=Jason, access=EXECUTE, inode="/history":root:supergroup:drwxrwx---
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkFsPermission(FSPermissionChecker.java:271)分析:线上/history/文件权限不足
1
2
3
4
5[root@xxo03 up]# hdfs dfs -ls /history/
Found 3 items
drwx--x--x - Jason supergroup 0 2016-05-21 18:43 /history/Jason
drwxrwx--x - root supergroup 0 2016-05-11 05:48 /history/history
drwx--x--x - root supergroup 0 2016-05-11 06:17 /history/root解决办法:添加权限给本地用户(Jason)
1
2
3
4
5
6
7
8[root@xxo03 /]# hdfs dfs -chmod -R a+x /history
[root@xxo03 /]# hdfs dfs -ls /
Found 5 items
-rw-r--r-- 1 root supergroup 57925 2016-05-09 07:40 /hadoop.log
drwxrwx--x - root supergroup 0 2016-05-21 18:43 /history
drwxr-xr-x - root supergroup 0 2016-05-11 06:25 /in
drwxr-xr-x - root supergroup 0 2016-05-11 07:11 /out
drwxr-xr-x - root supergroup 0 2016-05-11 06:17 /tmp项目源码下载:
http://download.csdn.net/detail/tang__xuandong/9527054