
Storm--实时数据处理框架
Storm 是Twitter开源的一个实时数据处理框架。Storm能实现高频数据和大规模数据的实时处理,很多人喜欢拿Hadoop来进行比较,其实他们差别挺大的,关键是应用场景不一样。
Storm简介
Storm与Hadoop区别主要有以下几点:
Storm应用场景总结:
- 数据流处理: 与其它流处理系统不同,storm不需要中间队列媒介
- 实时计算: 可连续不断的进行实时数据处理,把处理的结果实时更新展示到客户端
- 分布式远程过程调用: 可充分利用集群中CPU资源,进行CPU密集型计算。
Storm体系结构
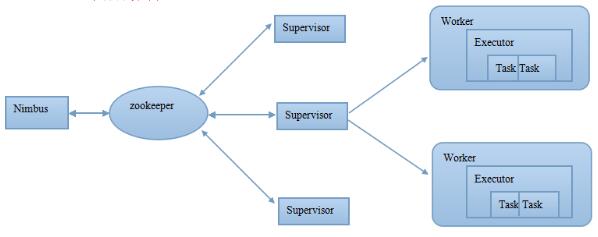
Nimbus:负责资源分配和任务调度。Zookeeper:负责Nimbus和多个Supervisor之间的所有协调工作。Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。Worker:工作进程,一个工作进程中可以含有一个或者多个Executor线程。Executor:线程,里面运行着多个Task。Task:worker中每一个spout/bolt的线程称为一个task. 一个task中一定是运行的是相同组件。
Storm组件

Topology : 用于封装一个实时计算应用程序的逻辑,类似于Hadoop的MapReduce Job;Stream : 消息流,是一个没有边界的tuple序列,这些tuples会被以一种分布式的方式并行地创建和处理;Spouts : 数据源,是消息生产者,他会从一个外部源读取数据并向topology里面面发出消息:tuple;Bolts : 处理消息,所有消息处理逻辑被封装在bolts里面,处理输入的数据流并产生新的输出数据流,可执行过滤,聚合,查询数据库等操作;Stream groupings : 消息分发策略,定义一个Topology的其中一步是定义每个tuple接受什么样的流作为输入,stream grouping就是用来定义一个stream应该如何分配给Bolts们。
集群搭建
- Storm是主从结构:主节点和工作节点
master节点:运行Nimbus进程,负责分发代码,安排任务,监控运行状态(主要是节点成功失败状态),一般还运行ui进程;worker节点:运行Supervisor进程,负责执行一个Topology的一个子集,一般还运行logviewer进程。
- 简单的介绍这基本安装
- 前提:安装zookeeper集群(注意:各集群节点时间保持一致)
- 下载上传解压apache-storm-0.9.3.tar.gz
- 修改文件conf/storm.yaml(实例中:一主两从节点,主节点为xxo08)
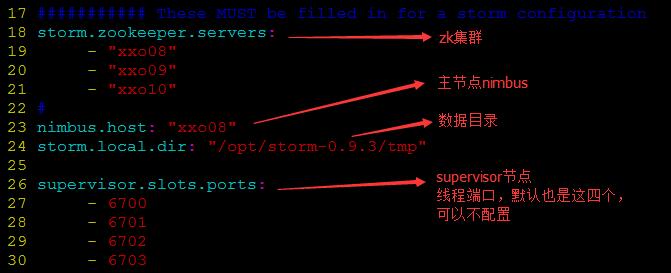
- 复制配置信息到其他节点(配置完全一样,scp即可)
- 启动:
5.1. 在主节点xxo08启动Nimbus进程、ui进程;
5.2. 在工作节点xxo09、xxo10启动Supervisor进程、logviewer进程;
eg:nohup /opt/storm-0.9.3/bin/storm nimbus >/dev/null 2>&1 &