
Storm--故障容忍和消息可靠性
如果Storm集群中某个Worker挂了会怎样?Nimbus和Supervisor挂掉了又会怎样?Storm流式处理数据又是怎样保证每条数据都能完全被处理的呢?这将是本博客讨论的重点,Storm的故障容忍,以及Storm的消息可靠性和Acker机制。
故障容忍
概念
Worker进程不会因Nimbus或者Supervisor的挂掉而受到影响
worker进程死掉: Supervisor会重启它。如果这个Worker连续在启动时失败,并且无法让Nimbus观察到它的心跳,Nimbus将这个Worker重新分配到另一台机器上。supervisor进程死掉: 这样不会影响之前已经提交的topology的运行,只是后期不会再向这个节点分配任务了。nimbus进程死掉: 这样不会影响之前已经提交的topology的运行,只是后期不能向集群中提交topology了。
Nimbus和Supervisor daemon进程,设计成快速失败(无论何时当遇到任何异常情况,将会执行自毁)和无状态(所有的状态都保存在Zookeeper或者磁盘上)。
- Nimbus和Supervisor daemon进程,必须在监控下运行,如使用daemontools或者monit工具。
- Nimbus是会有单点故障的问题,但Nimbus进程挂掉也不会引起任何灾难发生。
示例
- 我这里有一个一主两从的节点,从节点主机名为xxo09、xxo10。然后向集群中提交了一个求和的topology,如下图所示:

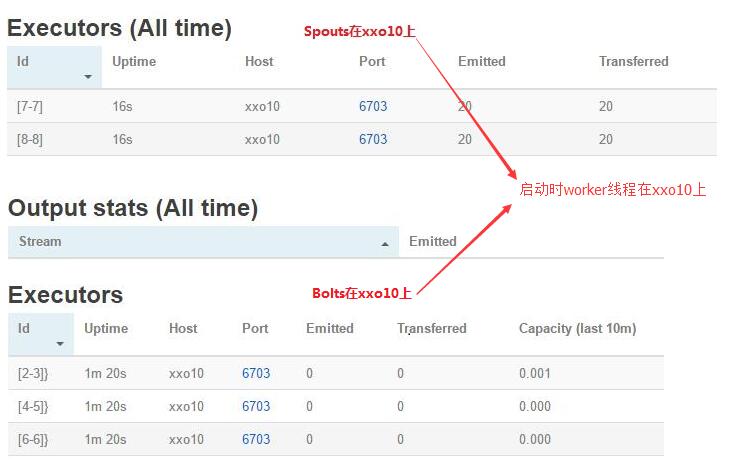
kill worker进程

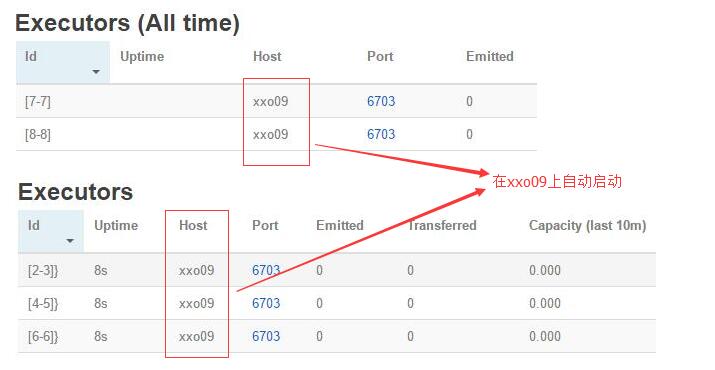
kill supervisor进程


消息可靠性
上面我们讨论了,storm的故障容错,下面我们继续来看一看strom是如何保证消息的可靠性的。
可靠性
- 在Topology中,Spout通过SpoutOutputCollector的emit()方法发射一个tuple(源)即消息。而后经过在该Topology中定义的多个Bolt处理时,可能会产生一个或多个新的Tuple。源Tuple和新产生的Tuple便构成了一个Tuple树。
- 当整棵Tuple树被处理完成,才算一个Tuple被完全处理,其中任何一个节点的Tuple处理失败或超时,则整棵Tuple树处理失败。
- Storm的消息可靠性 : 指的是storm保证每个tuple都能被toplology完全处理。而且处理的结果要么成功要么失败。出现失败的原因可能有两种即节点处理失败或者处理超时。
1
this.spoutOutputCollector.emit( new Values(i) );
可靠性设置
如何开启:在spout中发射数据的时候,带上messageid,messageid和tuple中的元素的关系需要程序员自己维护
1
this.collector.emit(new Values("num"),messageid)
如果对消息进去确认:这个工作其实是由acker线程进行追踪tuple的状态,
1
2
3
4
5
6
7
8
9
10
11
12//当在bolt中对数据处理成功的时候,需要调用
this.collector.ack(tuple) //这个时候,spout类中的ack方法会被调用。(这个方法是一个回调方法)
//如果在bolt中处理tuple的时候,最后没有调用ack方法(前提是:开起来acker消息确认机制)
//这个时候,当达到tuple的处理超时时间的时候,这个方法会被默认处理失败。这样spout类中的fail方法就会被调用。
config.put(Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS, 10); //设置超时时间
//针对多个bolt的topology,需要把bolt发射出来的tuple作为上一级tuple的一个衍生tuple,
//相当于把这些tuple组成一个tuple树,
//此时,只有所有衍生的tuple都调用ack方法的时候,spout中的ack方法才会被调用。保证tuple被完全处理
this.collector.emit(input,new Values(value));
acker示例
1 | package com.xxo.acker; |