
Java--HashMap笔记整理
一、 Map整体结构

- HashTable比较特别,作为类似Vector、Stack的早期集合相关类型,它是扩展了Dictionary类的,类结构上其他类明显不同,其他都扩展了AbstractMap。
- LinkedHashMap和TreeMap都可以保证某种顺序,但二者还是非常不同的。
二、 HashTable、HashMap、TreeMap都是最常见的一些Map实现,它们的简单区别?
- HashTable是早期Java类库提供的一个
哈希表实现,本身是同步的,不支持null键和值,由于同步导致的性能开销,所以已经很少被推荐使用。 - HashMap大致与HashTable一致,主要区别HashMap不是同步的,支持null键和值等。性能好,通常情况下,put、get可以达到常数时间的性能。
- TreeMap则是基于红黑树的一种提供顺序访问的Map,
get、put、remove之类操作都是O(log(n))的时间复杂度,具体顺序可以由指定的Comparator来决定,或者根据键的自然顺序来判断。
三、 HashMap内部的结构
- HashMap内部的结构,它可以看作是数组(Node<K,V>[] table)和链表结合组成的复合结构,数组被分为一个个桶(bucket),通过哈希值决定了键值对在这个数组的寻址;
哈希值相同的键值对,则以链表形式存储,如果链表大小超过阈值(TREEIFY_THRESHOLD, 8),图中的链表就会被改造为树形结构。
四、 哈希表
- 数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中)。在数组中根据下标查找某个元素,一次定位就可以达到。
- 同样哈希表如果不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1),因为哈希表的主干就是数组。
- 比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
存储位置 = f(关键字)
这个函数f一般称为哈希函数(哈希算法),哈希算法或散列函数可以将不定长的输入,通过散列算法转换成一个定长的输出,这个输出就是哈希值或散列值。这个函数的设计好坏会直接影响到哈希表的优劣。
如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的
哈希冲突,也叫哈希碰撞。- 好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀。但是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。
解决hash碰撞的方法有很多例如:链地址法,开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再哈希法,建立公共溢出区。参考:https://blog.csdn.net/sinat_37906153/article/details/83004831
HashMap即:采用了链地址法,也就是数组+链表的方式。
五、HashMap中的哈希函数
HashMap以jdk1.7 put为例:
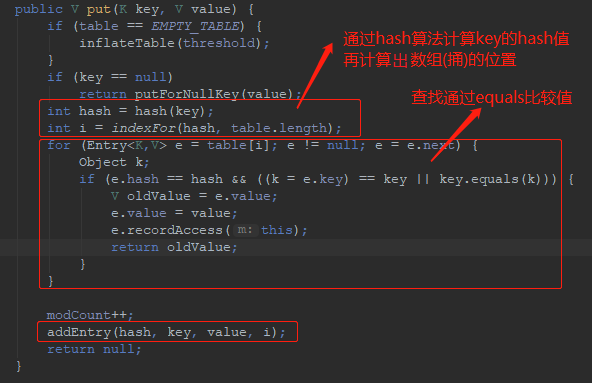
hash() 方法中使用扰动算法将 hashCode 的高位和低位混合起来:可以有效降低冲突概率。


注意:HashMap 的初始长度为 16,且每次扩容都必须以 2 的倍数(2^n)扩充。因为在 HashMap 中,采用按位与运算(&)代替取模运算(&),当 b = 2^n 时,a % b = a & (b - 1) 。
六、为何HashMap的数组长度一定是2的次幂?
- 如果数组进行扩容,数组长度发生变化,而存储位置 index = h&(length-1),index也可能会发生变化,需要重新计算index
- hashMap的数组长度一定保持2的次幂,比如16的二进制表示为 10000,那么length-1就是15,二进制为01111,同理扩容后的数组长度为32,二进制表示为100000,length-1为31,二进制表示为011111。从下图可以我们也能看到这样会保证低位全为1,而扩容后只有一位差异,也就是多出了最左位的1,这样在通过 h&(length-1)的时候,只要h对应的最左边的那一个差异位为0,就能保证得到的新的数组索引和老数组索引一致(大大减少了之前已经散列良好的老数组的数据位置重新调换)。以及使地位更加散列。参考:https://www.cnblogs.com/chengxiao/p/6059914.html
七、equals方法和hashCode方法,需要一起重写
- equals(Object obj)方法用来判断两个对象是否“相同”,如果“相同”则返回true,否则返回false。
- hashCode()方法返回一个int数,在Object类中的默认实现是“将该对象的内部地址转换成一个整数返回”。
- 重写equals但不重写hashCode,引发的问题
- 由于没有重写hashCode方法,所以put操作时,key(hashcode1)–>hash–>indexFor–>最终索引位置 ,而通过key取出value的时候 key(hashcode2)–>hash–>indexFor–>最终索引位置,由于hashcode1不等于hashcode2(默认返回内存地址转换后的整数),导致没有定位到一个数组位置而返回逻辑上错误的值null(但也有可能碰巧定位到一个数组位置)。
- 重写hashCode但不重写equals,引发的问题
- 同理,在取值时,做equals比较的时候由于equals1方法不等于equals2方法(默认使用‘==’来判断)所以会返回false。
- 注意:如果对象已经存在集合中,再去修改hashcode值的相关信息,会导致内存泄露问题。参考:https://blog.csdn.net/fmwind/article/details/76460681
八、JDK8中的HashMap
一直到JDK7为止,HashMap的结构都是这么简单,基于一个数组以及多个链表的实现,hash值冲突的时候,就将对应节点以链表的形式存储。
这样子的HashMap性能上就抱有一定疑问,如果说成百上千个节点在hash时发生碰撞,存储一个链表中,那么如果要查找其中一个节点,那就不可避免的花费O(N)的查找时间,这将是多么大的性能损失。这个问题终于在JDK8中得到了解决。再最坏的情况下,链表查找的时间复杂度为O(n),而红黑树一直是O(logn),这样会提高HashMap的效率。
JDK7中HashMap采用的是位桶+链表的方式,即我们常说的散列链表的方式,而JDK8中采用的是位桶+链表/红黑树的方式,也是非线程安全的。当某个位桶的链表的长度达到某个阀值的时候(默认8),这个链表就将转换成红黑树。红黑树:https://my.oschina.net/hosee/blog/618828

JDK8中Entry的名字变成了Node,原因是和红黑树的实现TreeNode相关联。transient Node<K,V>[] table;
当冲突节点数不小于8-1时,转换成红黑树。static final int TREEIFY_THRESHOLD = 8;
JDK8中的源码:
