
Java--ConcurrentHashMap笔记整理
- 讨论ConcurrentHashMap之前,我们首先了解一下java提供了那些不同层面上的线程安全的支持。了解一下大概的分类,然后在具体看ConcurrentHashMap的细节,分类如下:
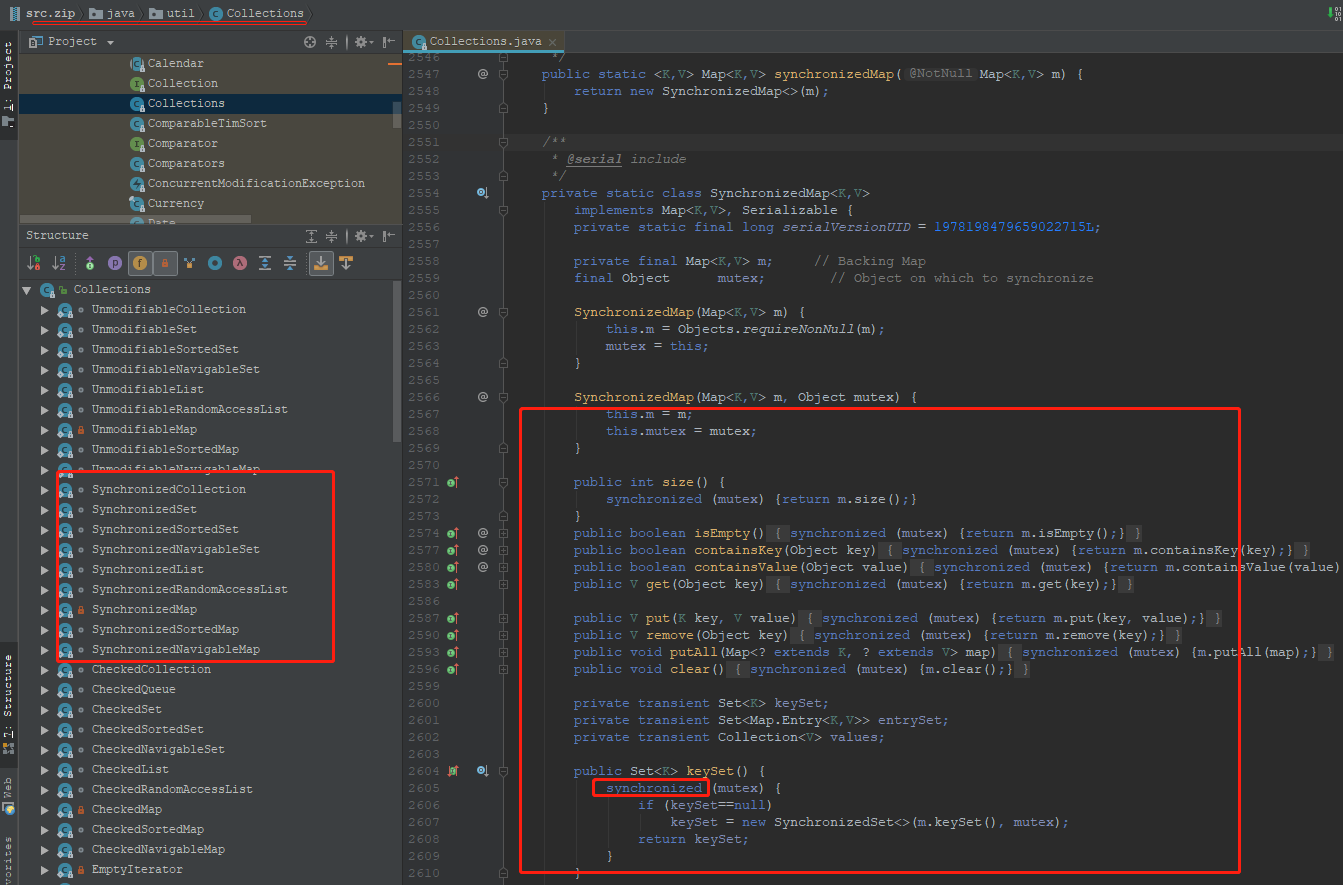
- 同步包装器(java.util.Collections工具类提供的包装方法),如Collections.synchronizedMap等,但是它们都是利用非常粗粒度的同步方式,在高并发情况下,性能比较低下。
- 并发包提供的线程安全容器类,这个应该是大多数人的选择:
- 各种并发容器,比如
ConcurrentHashMap、CopyOnWriteArrayList。 - 各种线程安全队列(
Queue/Deque),如ArrayBlockingQueue、SynchronousQueue。 - 各种有序容器的线程安全版本等。
- 各种并发容器,比如
为什么需要使用ConcurrentHashMap?
a. HashTable 主要是效率低(之前的文章提到过),因为它的实现基本就是将put、get、size等各种方法加上“synchronized”。简单来说,这就导致了所有并发操作都要竞争同一把锁,一个线程在进行同步操作时,其他线程只能等待,大大降低了并发操作的效率。
b. Collections 提供的同步包装器,只是利用输入Map构造了另一个同步版本,所有操作虽然不再声明成为synchronized方法,但是还是利用了“this”作为互斥的mutex,没有真正意义上的改进!
- 总结:上面两种方式只适合并发不太高的场景,所以需要使用ConcurrentHashMap,下面我们继续对ConcurrentHashMap进行探索。
Java7中的ConcurrentHashMap
- 在上一篇文章,在讲分段锁的时候提到过ConcurrentHashMap,主要也是在1.7中的实现,我们再来回顾一下。
ConcurrentHashMap主要使用分离锁(也叫分段锁,将内部进行分段(Segment)),内部存储结构是HashEntry数组+链表。
HashEntry内部使用volatile的value字段来保证可见性,也利用了不可变对象的机制以改进利用Unsafe提供的底层能力。在进行并发操作的时候,只需要锁定相应段,这样就有效避免了类似Hashtable整体同步的问题,大大提高了性能。
在构造的时候,Segment的数量由所谓的concurrentcyLevel决定,默认是16,也可以在相应构造函数直接指定。注意,Java需要它是2的幂数值,如果输入是类似15这种非幂值,会被自动调整到16之类2的幂数值。
下面看看java.util.concurrent.ConcurrentHashMap的源码:
- get操作需要保证的是可见性,所以并没有什么同步逻辑。
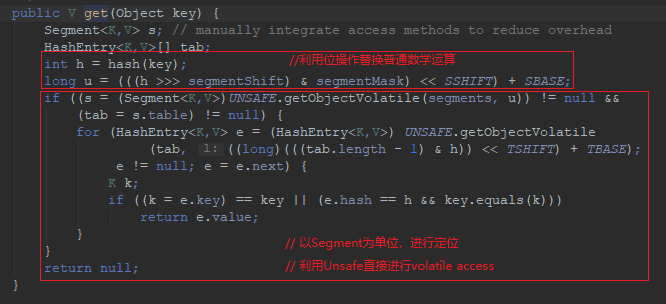
- 而对于put操作,以Unsafe调用方式,直接获取相应的Segment,然后进行线程安全的put操作:
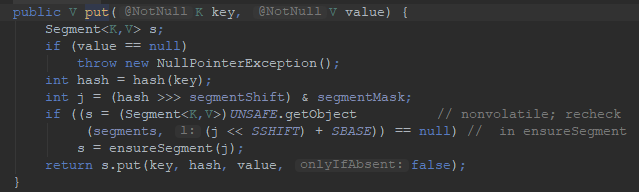

- 上面的源码清晰的看出,在进行并发写操作时:
- ConcurrentHashMap会获取再入锁,以保证数据一致性,Segment本身就是基于ReentrantLock的扩展实现,所以,在并发修改期间,相应Segment是被锁定的。
- 在最初阶段,进行重复性的扫描,以确定相应key值是否已经在数组里面,进而决定是更新还是放置操作,你可以在代码里看到相应的注释。重复扫描、检测冲突是ConcurrentHashMap的常见技巧。
- 与HashMap扩容区别是它进行的不是整体的扩容,而是单独对Segment进行扩容。
- 在上一篇文章中提到过它size方法的问题
如果不进行同步,简单的计算所有Segment的总值,可能会因为并发put,导致结果不准确,但是直接锁定所有Segment进行计算,就会变得非常昂贵。
所以,size()的实现是通过重试机制(RETRIES_BEFORE_LOCK,指定重试次数2),来试图获得可靠值。如果没有监控到发生变化(通过对比Segment.modCount),就直接返回,否则获取锁进行操作。
Java8中,ConcurrentHashMap发生了哪些变化呢?
总体结构上,非常相似,同样是大的桶(bucket)数组+链表结构(bin)
同步的粒度要更细致一些。
其内部仍然有Segment定义,但仅仅是为了保证序列化时的兼容性而已,不再有任何结构上的用处。
因为不再使用Segment,初始化操作大大简化,修改为lazy-load形式,这样可以有效避免初始开销,解决了老版本很多人抱怨的这一点。
数据存储利用volatile来保证可见性。
使用CAS等操作,在特定场景进行无锁并发操作。
使用Unsafe、LongAdder之类底层手段,进行极端情况的优化。
先看看现在的数据存储内部实现,我们可以发现Key是final的,因为在生命周期中,一个条目的Key发生变化是不可能的;与此同时val,则声明为volatile,以保证可见性。

直接看并发的put是如何实现的

1.1. 初始化操作实现在initTable里面,这是一个典型的CAS使用场景,利用volatile的sizeCtl作为互斥手段:如果发现竞争性的初始化,就spin在那里,等待条件恢复;否则利用CAS设置排他标志。如果成功则进行初始化;否则重试。

1.2. bin为空时,同样是没有必要锁定,也是以CAS操作去放置。
1.3. 在同步逻辑上,它使用的是synchronized,而不是通常建议的ReentrantLock之类,**这是为什么呢?现代JDK中,synchronized已经被不断优化,可以不再过分担心性能差异,另外,相比于ReentrantLock,它可以减少内存消耗,这是个非常大的优势。
与此同时,更多细节实现通过使用Unsafe进行了优化**,例如tabAt就是直接利用getObjectAcquire,避免间接调用的开销。

- 再来看看size的一些实现和改动
虽然思路仍然和以前类似,都是分而治之的进行计数,然后求和处理,但实现却基于一个奇怪的CounterCell。 难道它的数值,就更加准确吗?数据一致性是怎么保证的?
其实,对于CounterCell的操作,是基于java.util.concurrent.atomic.LongAdder进行的,是一种JVM利用空间换取更高效率的方法,利用了Striped64内部的复杂逻辑。这个东西非常小众,大多数情况下,建议还是使用AtomicLong,足以满足绝大部分应用的性能需求。
- (TODO:更多的细节还没写完,以后有时间的话再补充吧~)