OWL--监控系统实战六插件开发
该篇博客主要讲解:
- 开发owl插件的思路
- 开发一个Hadoop的owl插件的思路
- Hadoop owl插件的具体实现
监控系统实战七插件开发
开发owl插件的思路
写插件之前,先看一看owl里面已有的插件代码,看明白了就可以写自己的插件了

下面以check_mysql为例,看看源码:
main.go 主要就是组装参数,然后调用
FetchData1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25func main() {
app := cli.NewApp()
app.Name = "check_mysql"
app.Version = "0.1"
app.Usage = "mysql performance metric collector"
app.Authors = []cli.Author{
cli.Author{
Name: "yingsong",
Email: "wyingsong@163.com",
},
}
app.Copyright = "2011 (c) TalkingData.com"
app.Flags = []cli.Flag{
cli.StringFlag{
Name: "host",
Value: "127.0.0.1",
Usage: "Connect to host.",
EnvVar: "mysql_host",
Destination: &host,
},
// ......
}
app.Action = FetchData
app.Run(os.Args)
}mysql.go 就是组装Metric信息

- key.go 就是定义具体的实体类型
看完代码后,大概知道怎么写了,然后运行起来看看效果
插件怎么运行?
- 进入插件目录然后
go build,会出来一个可执行的文件,然后放入到指定目录(agent执行文件同级的plugins/目录下)就okay.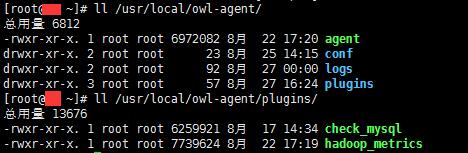
- 进入插件目录然后
具体的调用和插件metrics的输出在agent task.go里面

Hadoop插件的思路
常见的Hadoop监控平台
- 常见的发行版
CDH,监控管理平台cloudera manager,或则Ganglia等。就展示了各种信息(内存,cpu…) - 所以Hadoop平台的信息,肯定是可以采集的。我们要做的就是和它一样,
做一个属于自己的cloudera manager
收集的方式
- 怎么收集hadoop平台的metrics信息?有两种方式
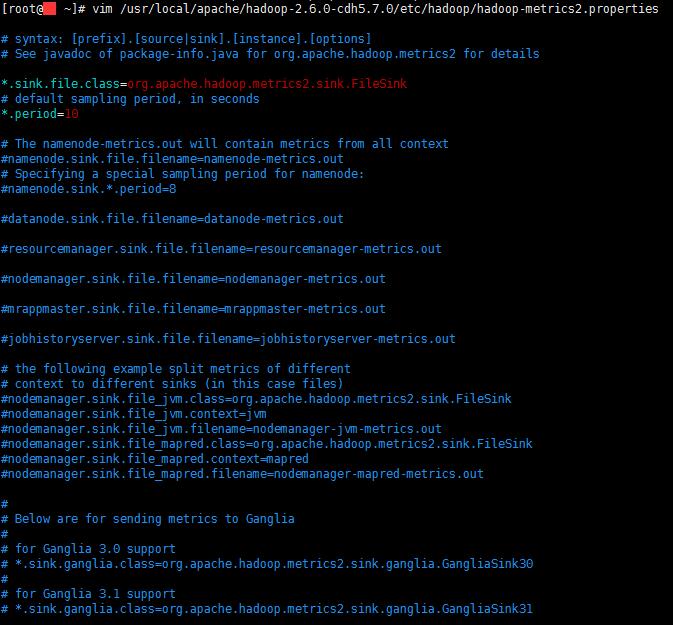
通过实现接口方式,然后重写
putMetrics等方法,就像源码中的FileSink,Ganglia等- 下图示例是写入文件,我们要做的就是写入到opentsdb里面就行

- 写完后打包成jar,放到hadoop平台。然后修改metrics2配置文件
通过jmx信息收集平台信息
- 一般地址是http://ip:port/jmx,比如NameNode服务jmx信息:

- 上面两种方式选择哪一种?第一种方式直接写入到opentsdb但是还得去维护一下owl MySQL的元数据信息,第二种方式直接写插件收集就行,下面的示例选择的是第二中方式。
jmx数据的解析
我们可以看见jmx是一个超级大的json,仅仅DataNode就有40个items,而且每一个json不是那么有规律。

我把全部json看了一遍,发现并不是所有都是我们需要的数据,像下面这种即使解析后放入到owl也是没有意义的,没法计算!

我们只需要解析出我们想要的数据就行,就这样开发了一个自己的
cloudera manager
于是可以通过定义一些模板的方式,去获取想要的数据。
- 因为发现
modelerType是唯一的,模板中我们就可以通过该值去json中匹配,然后解析对应的json - 解析对应的json,我们也可以定义成一个实体出来,而且还可以在里面赛选需要的字段
- 因为发现
最终的数据是要转换成metrics结构的数据
- metrics name :我们也需要定义出来一个通用的规则,方便统一管理和代码的编写
- metrics type :我们也要考虑到每一个字段统计的方式不同,的和字段绑定在一起,所以可以定义到上面json解析的字段实体中
- metrics tags :这个我们可以获取json中,jsonK以“tag.”开头的数据
- metrics value:这个得考虑到hadoop平台中的一些单位的统一,有GB、MB、纳秒等
具体的实现
结构体的定义
- 结构肯定是一个map结构的(modelerType,json字段对应的实体):map[string]interface{}
- json字段对应的实体(json字段,metrics type)最终结构:map[string]map[string]string
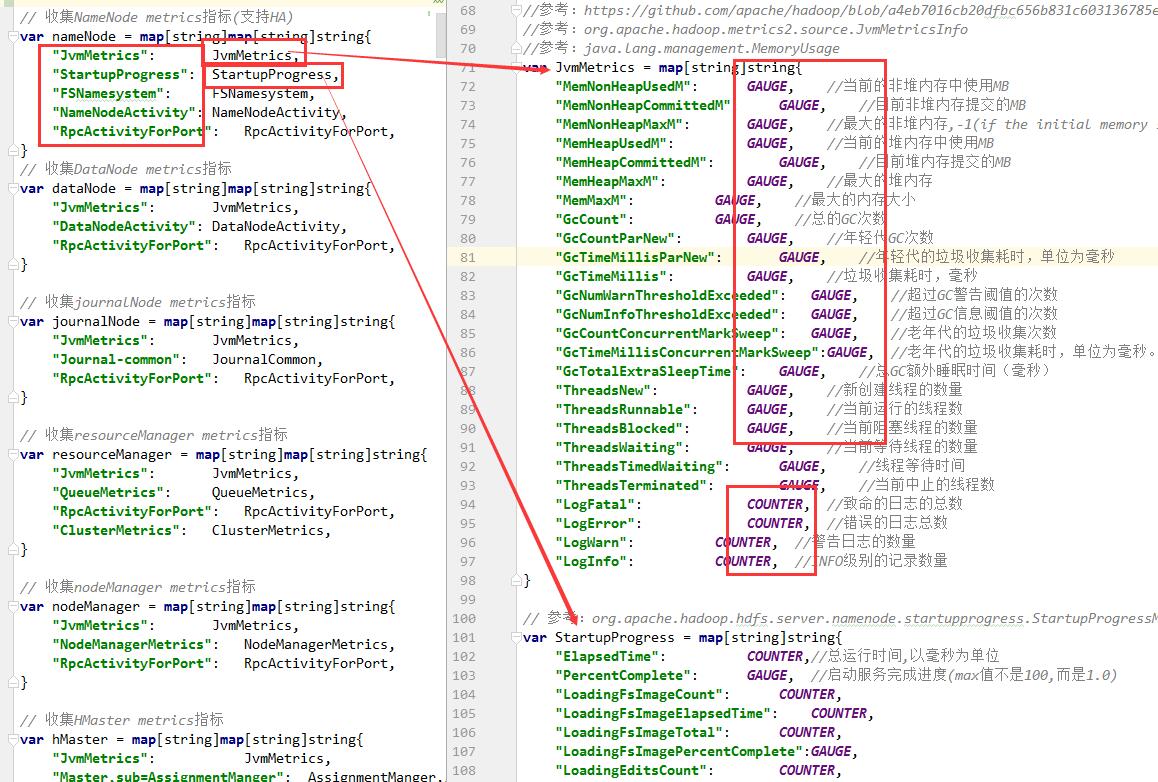
- 发现实体代码有点多copy麻烦,自己写了一个工具类生成的代码,
metrics type在源码里面都有具体的类型可以参考。
http请求与json转换
1 | // http get请求 |
解析数据
通过定义的
modelerType去匹配json的字段value1
strings.HasPrefix(maps["modelerType"].(string),prefix)
解析jmx tags
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29/**
metrics: {
metric:prefix.map.k(排除tag开头的map.k)
Value:map.v
tags:{tag开头的map.k,map.v,service:service}
}
*/
// 如果是Master,sub=AssignmentManger这种样式的我们就用tag.Context来作为metric前缀
// HBase的modelerType比较特殊
if strings.Contains(prefix,",sub=") {
prefix = maps["tag.Context"].(string)
}
// 获取tags and 组装tags
tags := make(map[string]string)
for k,v :=range maps {
if strings.HasPrefix( k,"tag." ) && v != nil {
tags[strings.ToLower(strings.TrimPrefix( k,"tag." ))] = v.(string)
}
}
for _,v := range strings.Split(maps["name"].(string),",") {
splits := strings.Split(v, ":")
if len(splits) == 2 {
tags[strings.Split(splits[1],"=")[0]]=strings.Split(splits[1],"=")[1]
}
}组装metrics信息
1
2
3
4
5
6
7
8
9
10for k,m :=range fields {
if maps[k] != nil {
data = append(data, Metric{
Metric: prefix+"."+k,
DataType: m,
Value: conversionBytes(k,maps[k]),
Tags: tags,
})
}
}
数据单位换算
- 大小转换为KB,时间转换为毫秒秒
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27func conversionBytes( k string, v interface{} ) interface{}{
// MB
if strings.HasSuffix(k,"M") || strings.HasSuffix(k,"MB"){
vf, err := v.(json.Number).Float64()
if err == nil && vf > 0{
v = vf*MB
}
}
// GB
if strings.HasSuffix(k,"GB") {
vf, err := v.(json.Number).Float64()
if err == nil && vf > 0{
v = vf*GB
}
}
// 纳秒
if strings.Contains(k,"NanosAvgTime"){
vf, err := v.(json.Number).Float64()
if err == nil {
v = vf/NANOS
}
}
return v
}
参数的设置
- 第一个参数就是url,即指定到具体的jmx信息
- 第二个参数service,就是服务的映射,你需要具体解析那些服务

- 插件的配置

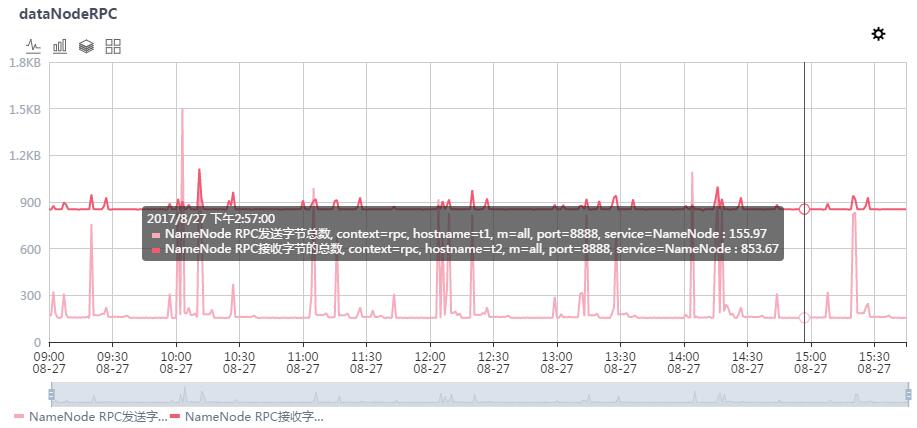
效果
- 看看效果吧!这就是我们自己的cloudera manager