
Hadoop--MapReduce源码分析
本片博客Hadoop的MapReduce源码分析,主要对上篇博客Hadoop-MapReduce详解/做进一步的理解。MapReduce源码分析东西太多,截图都截累了,前面比较详细一点靠后面可能只把主要的贴了上来,空闲了我在做一些补充吧!
- MapReduce过程概述:
- Job提交任务,会做初始化配置文件、检查Output Path、请求RM获取JobId、复制资源文件到HDFS等操作然后提交job作业;
- RM接收到作业后会初始化Job对象,然后启动一个NM会从HDFS获取资源文件分配一个Container,在Container中启动一个AM,在过程中会把文件分割为多个输入分片;
- 每个输入分片会让一个map任务来处理,输出多个键值对,输出的结果会暂且放在一个环形内存缓冲区中;
- 紧接着就是分区,目的是把k2分配到不同的reduce task;
- map输出时可能会有很多的溢出文件,要将这些文件合并。合并的过程中会不断地进行排序和combia操作,最后合并成了一个已分区且已排序的文件。
- reduce阶段,接收到不同map任务传来的数据,如果接收数据大超过阈值就会溢出写入磁盘,溢出文件增多合并成大的有序的文件(反复地执行排序,合并操作)
- MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。

Job提交作业

Job开始提交任务
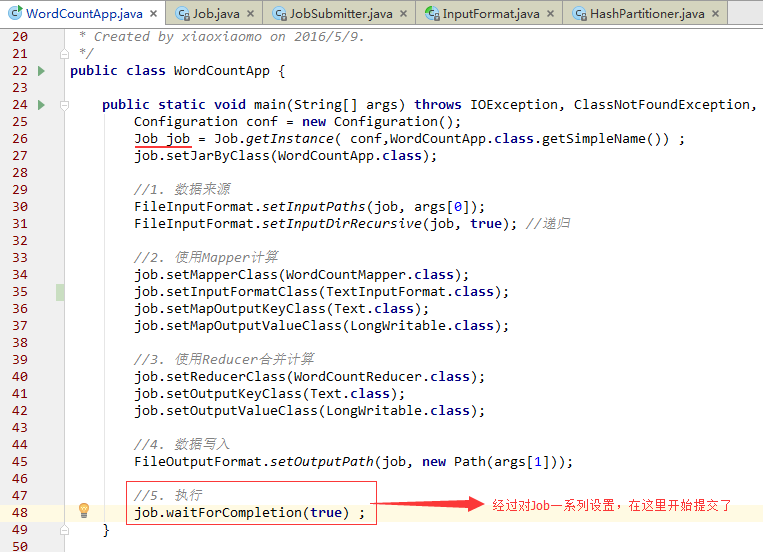
接下来我们进入Job类看一看waitForCompletion方法,waitForCompletion方法中主要调用了两个方法:
submit()和monitorAndPrintJob(),如下图所示:
submit方法
- 在waitForCompletion中,我们先看一看submit方法,该方法主要提交Job,调用JobSubmitter.submitJobInternal()方法完成
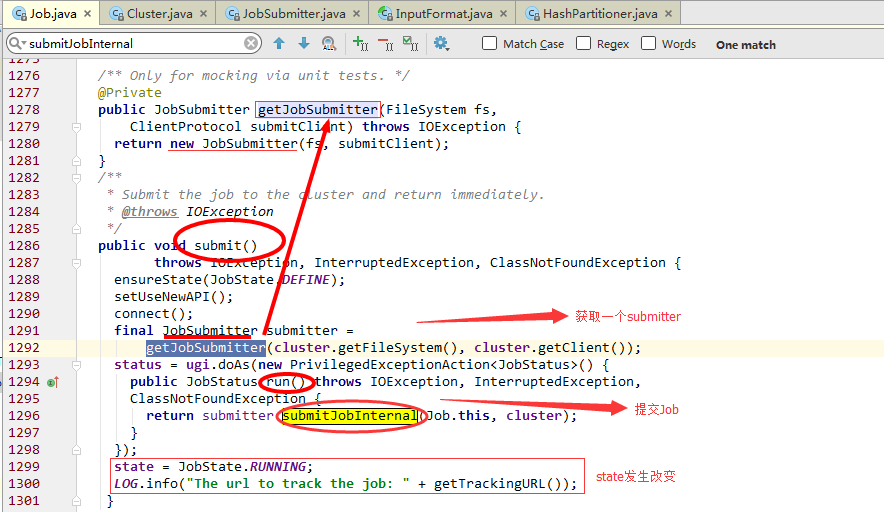
submitJobInternal
submitJobInternal(),主要有以下几个主要功能:
1、会检查job的Output Path;
2、设置Job ID
3、设置Job 命令选项
4、分割、切片并创建splits文件
5、复制配置文件到HDFS
6、正在的提交Job具体代码如下:
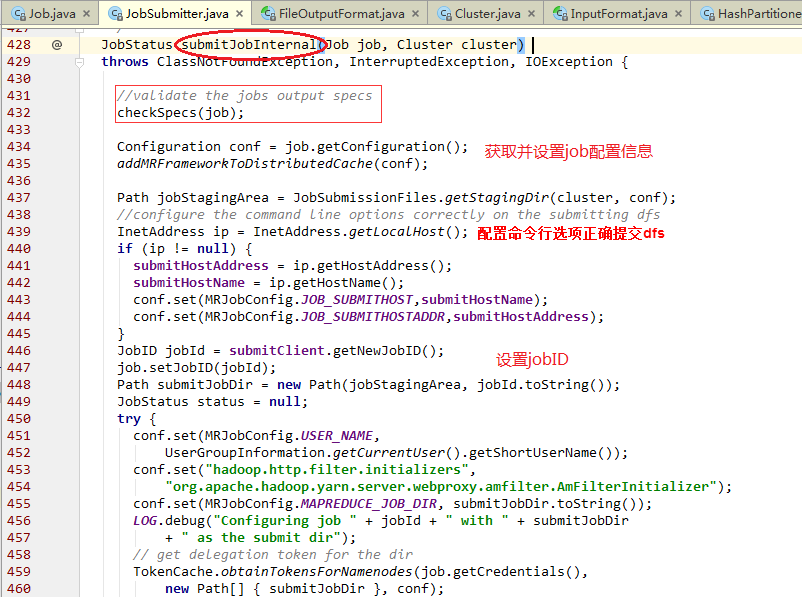

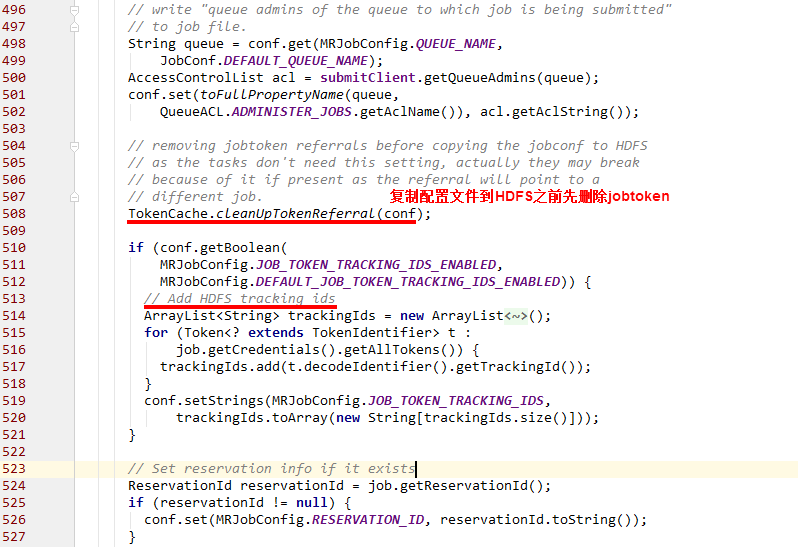

- checkSpecs() 方法检查output文件;
- setJobID() 设置Job ID;
- writeSplits() 写Splits文件;
- cleanUpTokenReferral() 清除jobtoken referrals;
- writeConf() 写入job相关的配置文件到HDFS;
- submitClient.submitJob() 做真正的提交Job。
writeSplits
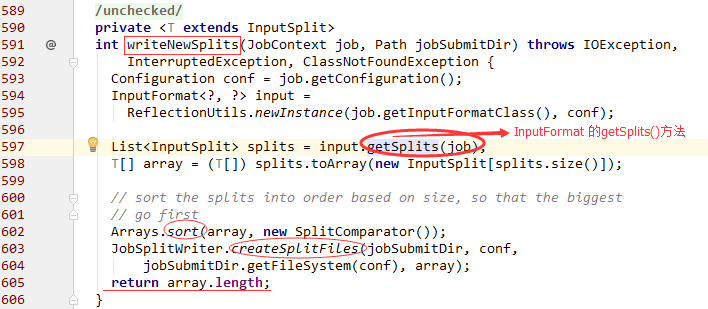
在看submitClient.submitJob()之前我们先看一看分割、切片 writeSplits() 方法

writeSplits下面调用了writeNewSplits()和writeOldSplits()方法,我们只看一个writeNewSplits方法:
- 通过InputFormat的getSplits()方法获取一个List
- 排序后再创建SplitFiles
InputFormat
InputFormat抽象类仅有两个抽象方法:
- List
getSplits() , 获取由输入文件计算出输入分片(InputSplit),解决数据或文件分割成片问题。 - RecordReader<K,V> createRecordReader(),创建RecordReader,从InputSplit中读取数据,解决读取分片中数据问题
- 具体完成以下功能:
3.1. 验证作业输入的正确性
3.2. 将输入文件切割成逻辑分片(InputSplit),一个InputSplit将会被分配给一个独立的MapTask
3.3. 提供RecordReader实现,读取InputSplit中的“K-V对”供Mapper使用
- 一、getSplits()
一.1、getSplits()是InputFormat接口的抽象方法,所以我们在具体InputFormat的实现类下面的实现方法就行了,如下图:

一.2、下面我们来看看FileInputFormat在这里,记得弄清楚Splits和Block的关系


- 一个InputSplit对应一个Map Task ;
- 默认文件可分割(true),这样一个block(128MB)就对应一个InputSplit(通过computeSplitSize(…)方法);
- 通过分析while循环,得知一个InputSplit对应一个block有利于map计算的数据本地化;
- 如果文件不允许分隔,整个文件作为一个InputSplit,这样一个InputSplit就可能对应多个block。
注意:getSplits完成后返回一个List InputSplit,然后对它进行排序sort和创建Split文件createSplitFiles具体的排序算法这些博主就不一一贴图了,比较好理解,大家可以自己去看看。
提交JOB到RM
下面看一看ClientProtocol 提交Job submitJob的实现类YARNRunner,主要是提交Job到ResourceManager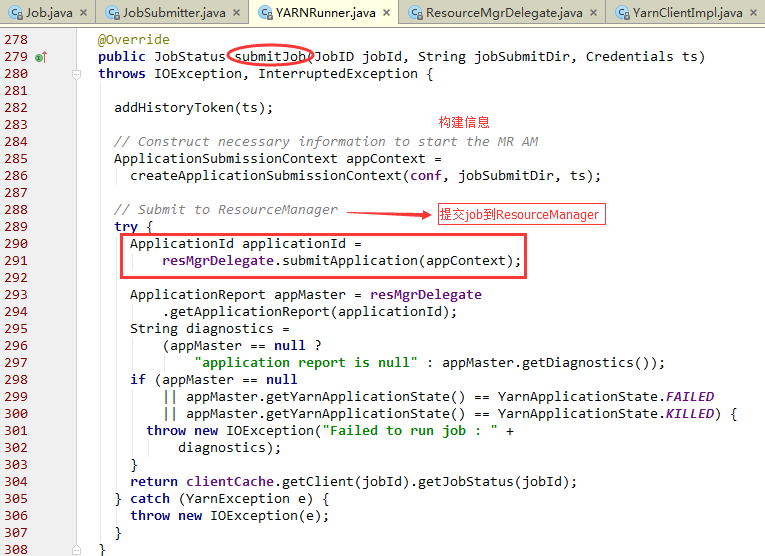
monitorAndPrintJob
- 上面submit方法已经提交job了,该方法就是做一些监控,并打印日志信息


读取InputSplit中的数据
- 读取InputSplit中的数据,转成k1,v1 ,由LineRecordReader完成,存在于TextInputFormat。
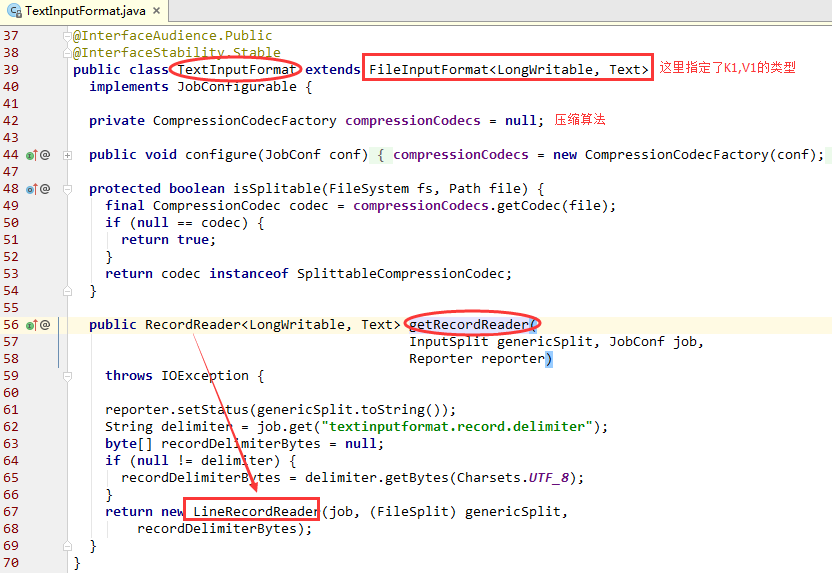
- TextInputFormat方法 相当于一个解释器,有很多的解释器,TextInputFormat为默认的文本解释器;
- TextInputFormat方法 重写了isSplitable方法和 RecordReader 方法()相当于定义了自己的规则;
- getRecordReader方法 最后返回了一个LineRecordReader的实例。
注:我们的job程序默认使用的就是TextInputFormat,该类的泛型已经明确指定了,所以在job配置的时候,不需要指定k1,v1的类型。
- 下面我们来一起看一看LineRecordReader类:

先看看父类RecordReader 因为比较清晰明了,这几个方法很重要,如下图所示:

返回LineRecordReader,看一看大致有哪些具体实现
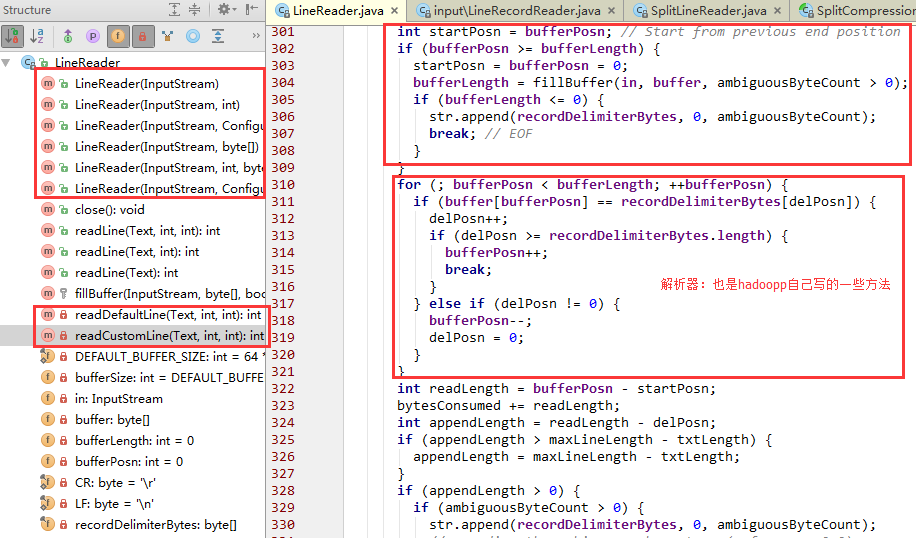
看一看几个重要的方法,如下图源码每次调用nextKeyValue()时,value表示当前行的内容,key表示已经读取后的位置具体实现:
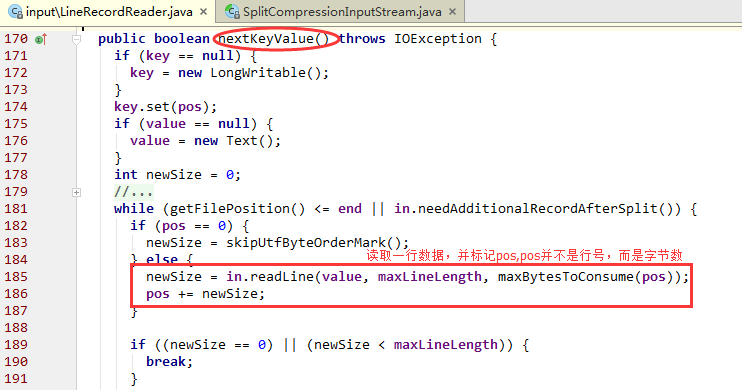
在MR框架中,有很多InputFormat和FileInputFormat的实现类。比如SequenceFileInputFormat,NLineInputFormat、DBInputFormat等。DBInputFormat表示从SQL表中读取数据,可以看出我们不仅仅是从HDFS中取数据作为输入还可以从数据库中读取数据,来一个简单的截图:
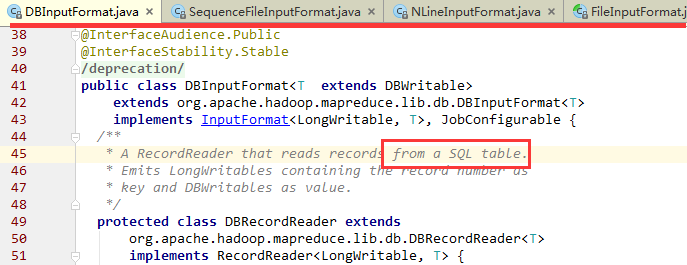
执行map task
- 在我们写代码的时候,可以覆盖setup、map、cleanup方法;
框架调用map的时候,是通过反射的方式产生的,然后调用实例化对象中的run()。
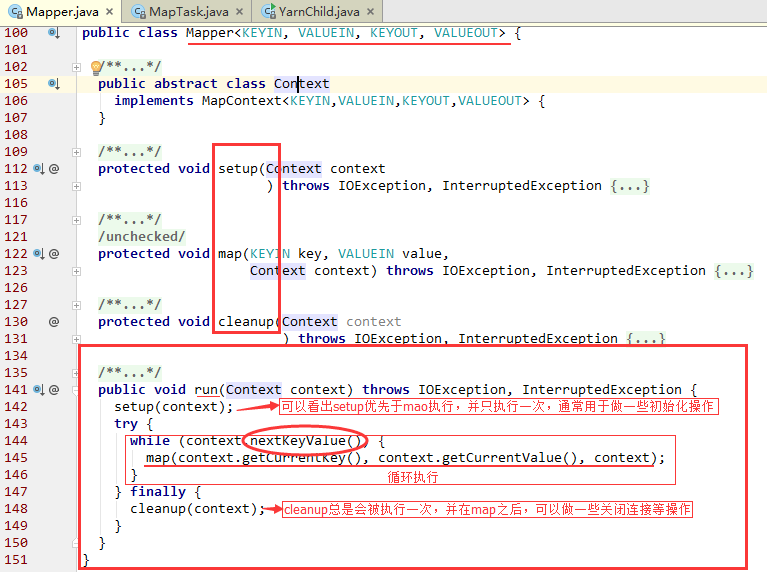
注意我们Mapper类的write()方法,其实是调用了
org.apache.hadoop.mapreduce.Mapper.Context
- 程序真正执行时,是启动了一个YarnChild类,下面我们来分析框架如何调用map task或者reduce task。
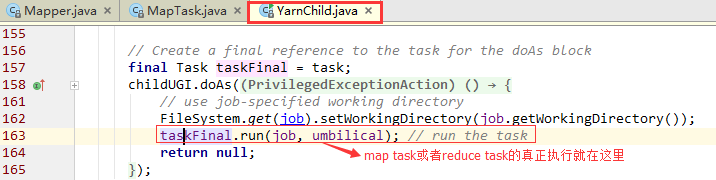
看一下taskFinal的一个实现类是MapTask。

继续分析下面的runNewMapper()方法


在这里可以看出:如果没有reduce task,那么map直接把<k2,v2>输出。如果有,创建排序的输出。
在这里,output实际上是WordCountMapper类中的map()方法里面的context.write()实际调用,就是在output中调用的。接下来分析NewOutputCollector类的实现的构造方法,partitioner类是在这里实例化的。

分区
我们还是在NewOutputCollector方法里主要看看write(…)方法。

当在WordCountMapper类的map()方法中调用context.write(…)的时候,实际上是调用collector.collect(…) ,在这个方法的形参中,第三个参数就是分区。

在这里collector的实现类是MapOutputBuffer类。

排序
- 我们就到了SpillThread类,接下来分析SpillThread类,直接看run()方法,代码比较简洁:

- 继续分析sortAndSpill()方法,可以看到,在spill之前,会先进行sort操作。

合并
- 现在我们任然在SpillThread类里面,继续看下面的代码:

上面的代码说明:如果没有combiner,直接把<k2,v2>写入到磁盘。如果有combiner,先执行combiner再写入磁盘。
写入磁盘(spill)
- 写入磁盘(spill),实际上是通过调用InMemoryWriter来实现的。

reduce的全过程
上面已经把map的过程走完了,截图真累!!下面我们简单看看Reduce吧!Reducer和Mapper很类似,这里就不一一解释了:

直奔主题ReduceTask的run()方法

继续向下看代码。

查看shuffleComsumerPlugin.run()的时候,跳转到Shuffle类中。
