
Hadoop-HDFS架构和Shell
Hadoop分布式文件系统(HDFS),一个高度容错性的系统,适合部署在廉价的机器上。HDFS提供了高吞吐量的数据访问,适合大规模数据集的应用。HDFS采用master/slave架构,HDFS集群是由一个NameNode和一定数目的DataNodes组成。
HDFS架构和设计

硬件错误:
硬件错误是常态而不是异常。HDFS可能由成百上千的服务器所构成,每个服务器上存储着文件系统的部分数据,面对成百上千的服务器,难免会出现某些主件出现异常现象。对于Hadoop来说错误检测和快速、自动的恢复是它最核心的架构目标。大规模数据集:
在HDFS上文件大小一般都在G字节至T字节,于是HDFS被调节以支持大文件存储。能在一个集群里扩展到数百个节点,具有很大的数据集。流式数据访问:
HDFS的设计中更多的考虑到了数据批处理,而不是用户交互处理。比之数据访问的低延迟问题,更关键的在于数据访问的高吞吐量。一致性模型:
一次写入多次读取的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。移动计算:
一个应用请求的计算,离它操作的数据越近就越高效,在数据达到海量级别的时候更是如此。因为这样就能降低网络阻塞的影响,提高系统数据的吞吐量。将计算移动到数据附近,比之将数据移动到应用所在显然更好。平台移植:
HDFS在设计的时候就考虑到平台可移植性。这种特性方便了HDFS作为大规模数据应用平台的推广。
FS Shell
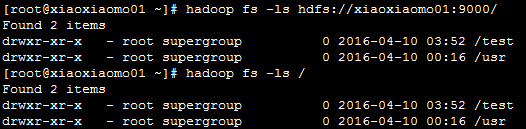
(FS)Shell命令应使用bin/hadoop fs <args>的形式。 所有的shell命令使用URI路径作为参数。eg:hadoop fs -ls hdfs://xiaoxiaomo01:9000/
- 所用(FS)Shell命令都是以
“hadoop fs”开头(1.0),2.0修改为“hdfs dfs”开头。- -ls 为命令选项,记住和linux里面是有区别的,
这里每个命令前面有“-”。- xiaoxiaomo01是我hadoop的主机名。
- hdfs://xiaoxiaomo01:9000/可简写为“/”,> hadoop fs -ls /
例如
(FS)Shell命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18-help [cmd] //显示命令的帮助信息
-ls(r) <path> //显示当前目录下所有文件
-du(s) <path> //显示目录中所有文件大小
-count[-q] <path> //显示目录中文件数量
-mv <src> <dst> //移动多个文件到目标目录
-cp <src> <dst> //复制多个文件到目标目录
-rm(r) //删除文件(夹)
-put <localsrc> <dst> //本地文件复制到hdfs
-copyFromLocal //同put
-moveFromLocal //从本地文件移动到hdfs
-get [-ignoreCrc] <src> <localdst> //复制文件到本地,可以忽略crc校验
-getmerge <src> <localdst> //将源目录中的所有文件排序合并到一个文件中
-cat <src> //在终端显示文件内容
-text <src> //在终端显示文件内容
-copyToLocal [-ignoreCrc] <src> <localdst> //复制到本地
-moveToLocal <src> <localdst>
-mkdir <path> //创建文件夹
-touchz <path> //创建一个空文件
上述的命令需要多去练习,下面据简单的举例一下上传下载,创建文件,移动复制,事例如下:
创建文件夹

说明:我们首先递归查看了/test文件夹,下面只有一个文件,然后在该目录下创建了/momo目录上传文件到指定目录(上传文件到momo目录)


下载文件

移动文件夹

复制文件

Namenode
Namenode,是整个文件系统的管理节点;- 它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表,接收用户的操作请求;
- NameNode 只有三种交互。
3.1. client访问NameNode获取相关DataNode信息。
3.2. DataNode心跳汇报当前block情况。
3.3. SecondaryNameNode做checkpoint交互。
Datanode
- Datanode:提供真实文件数据的存储服务
文件块(block):最基本的存储单位。HDFS默认Block大小是64MB(1.0版本),128(2.0版本),如果一个文件小于一个数据块的大小,HDFS并不占用整个数据块存储空间。
Replication:多复本,默认是三个。
SecondaryNameNode
- HA的一个解决方案。但不支持热备。配置即可
执行过程:从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits.(默认在安装在NameNode节点上,但这样…不安全!)
- 参考资料