
Spark Streaming--应用与实战(一)
接下来的几篇博客是一个连续的部分,主要分为了:
- SparkStreaming-应用与实战(一),讲解背景与架构改造,以及为什么使用spark streaming
- SparkStreaming-应用与实战(二),通过代码实现具体细节,并运行项目
- SparkStreaming-应用与实战(三),对streaming监控的介绍以及解决实际问题
- SparkStreaming-应用与实战(四),对项目做压测与相关的优化
- SparkStreaming-应用与实战(五),Streaming优化之HBase
- SparkStreaming-应用与实战(六),Streaming任务的管理及监控
一、背景
- 笔者所在部门
宜人蜂巢,是由李善仁 宜人贷副总裁,宜人蜂巢负责人 2013年创建。宜人蜂巢是做什么的?笔者在这里简单表述一下宜人蜂巢– 数据科学驱动的互联网风控解决方案,通过千万级爬虫并发技术、计算机视觉技术、机器学习技术等;实时数据采集源;鲜活信用分析特征提取;多维度特征下的欺诈行为交叉检测等一系列科技手段助力金融生态和谐健康发展。 - 在大数据风控领域,数据是一切工作的根基。数据量的多少、维度的多少,抓取的速度、成功率都是评判数据质量、获取能力的重要条件。在经过用户授权的情况下,宜人蜂巢可以实现对“社交、电商、金融、信用、社保”五大维度的实时数据抓取。宜人蜂巢正在积极与银行、电商、电信运营商、保险公司以及社保基金等机构展开合作,进一步提高数据抓取的工作效率。
- 所以在大量数据获取之后,对于底层的数据存储依赖也是相当高的,传统的数据库已经没法在支持,对底层数据服务架构的改造迫在眉睫。
二、问题描述
宜人蜂巢之前的数据数据服务主要是支撑爬虫服务的,“宜人蜂巢爬虫”抓取的数据通过大数据这边提供的SOA服务入库到HBase,架构大致如下:
以对于以上的架构存在一些问题,我们可以看见数据在Dubbox服务阶段处理后直接通过HBase API入库了HBase,中间并没做任何缓冲,要是HBase出现了问题整个集群都完蛋,没法写入数据,数据还丢失,HBase这边压力也相当大,针对这一点,对入库HBase这个阶段做了一些改造。
三、架构改造
改造后的架构,爬虫通过接口服务,入库到Kafka,Spark streaming去消费kafka的数据,入库到HBase.核心组件如下图所示: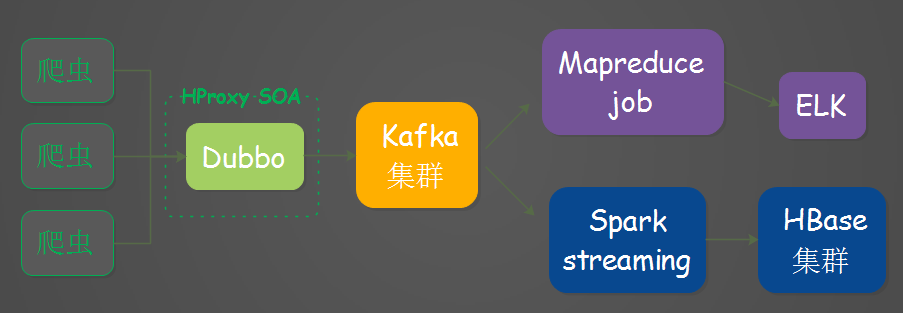
- 为什么不直接入库到HBase,这样做有什么好处?
- 缓解了HBase这边峰值的压力,并且流量可控
- HBase集群出现问题或者挂掉,都不会照成数据丢失的问题
- 增加了吞吐量
四、 为什么选择Kafka和Spark streaming
- 由于Kafka它简单的架构以及出色的吞吐量.
- Kafka与Spark streaming也有专门的集成模块.
- Spark的容错,以及现在技术相当的成熟.