
Spark--从RDD的角度来看Spark内部原理
- 上篇博客主要讲了Spark的执行流程,看完后应该是对Spark有一个整体的了解,对Spark各个组件的工作流程都应该是有一个很清晰的认识了。
本篇博客,笔者主要是继续接着“宜人蜂巢内部分享”,从RDD的角度来看Spark的内部原理,包括以下内容:
- RDD为什么是Spark的核心概念
- 通过一个wordCount例子来看一看RDD
- RDD的管理与操作(算子)
- 常见的RDD操作有哪些(包括RDD的分类)
- RDD的依赖关系(DAG)
- RDD依赖关系的划分(stage)
RDD为什么是Spark的核心概念
Spark建立在统一抽象的RDD之上,使得Spark可以很容易扩展,比如 Spark Streaming、Spark SQL、Machine Learning、Graph都是在spark RDD上面进行的扩展(可以看见RDD的核心地位了吧)- RDD是什么呢?理解一下概念:
- RDD(Resilient Distributed Dataset):弹性分布式数据集。
- RDD是只读的,由多个partition组成
- Partition分区,和Block数据块是一一对应的

通过一个wordCount例子来看一看RDD
- 上面只是RDD的概念,下面举个wordCount的例子来说明一下:
1
2
3val file = sc.textFile("hdfs://data/test.txt")
val data = file.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)

- Spark 程序具体的流程图
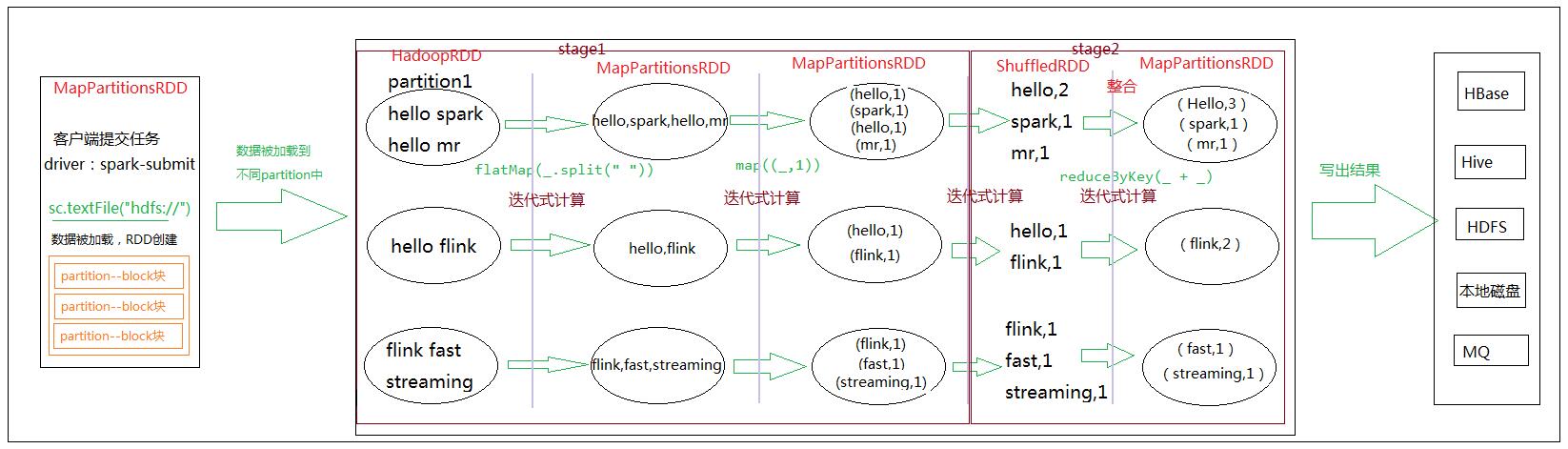
- 客户端提交任务,初始化sparkContext之后,sc.textFile(“hdfs://“),去hdfs加载文件
- 加载的文件比如有300MB,在hdfs中就有3个block块,对应 RDD 里面的三个partition
加载的这个过程其实就是RDD的创建(MapPartitionsRDD)- 数据被加载到不同的partition中,通过构建的stage(task set)然后提交到executor中去并行计算
- 计算完成后输出结果
- 在整个spark计算流程里面,RDD起到了一些什么作用?
作用当然大了!可以看出整个计算流程都是基于RDD在做计算,从数据加载,即RDD的创建,中途的计算(stage的划分,RDD的操作,shuffle)。到最后结果的输出,整个计算流程都是由RDD在贯穿
写博客其实挺累的,太耗时了
…
继续吧,既然已经开始…..
RDD的管理与操作(算子)
- RDD管理
- RDD是一个分布式数据集,即数据分布存储在多台机器上。从上面也可以看到,每个RDD的数据都以Block的形式存储于多台机器上
- 在Spark任务运行时
- Driver 节点的BlockManagerMaster保存Block的元数据,并且管理RDD与Block的关系。
- Executor 会启动一个BlockManagerSlave,管理Block数据并向BlockManagerMaster注册该Block
- 当RDD不再需要存储的时候,BlockManagerMaster将向BlockManagerSlave发送指令删除相应的Block。

RDD操作
RDD还提供了一组丰富的操作来操作这些数据,这种操作叫做算子。比如map、flatMap、filter、join、groupBy、reduceByKey等RDD分类,分为创建算子、转换、缓存、执行
Transformation:转换算子,这类转换并不触发提交作业,完成作业中间过程处理。Action:行动算子,这类算子会触发SparkContext提交Job作业。
常见的RDD操作有哪些(包括RDD的分类)
常见的算子,如下图所示:

具体的来看一下,例如map算子示例如下:

RDD的依赖关系(DAG)
- RDD的依赖关系有两种:窄依赖(narrow dependency)和宽依赖(wide dependency)。
窄依赖:每一个parent RDD的Partition最多被子RDD的一个Partition使用宽依赖:多个子RDD的Partition会依赖同一个parent RDD的Partition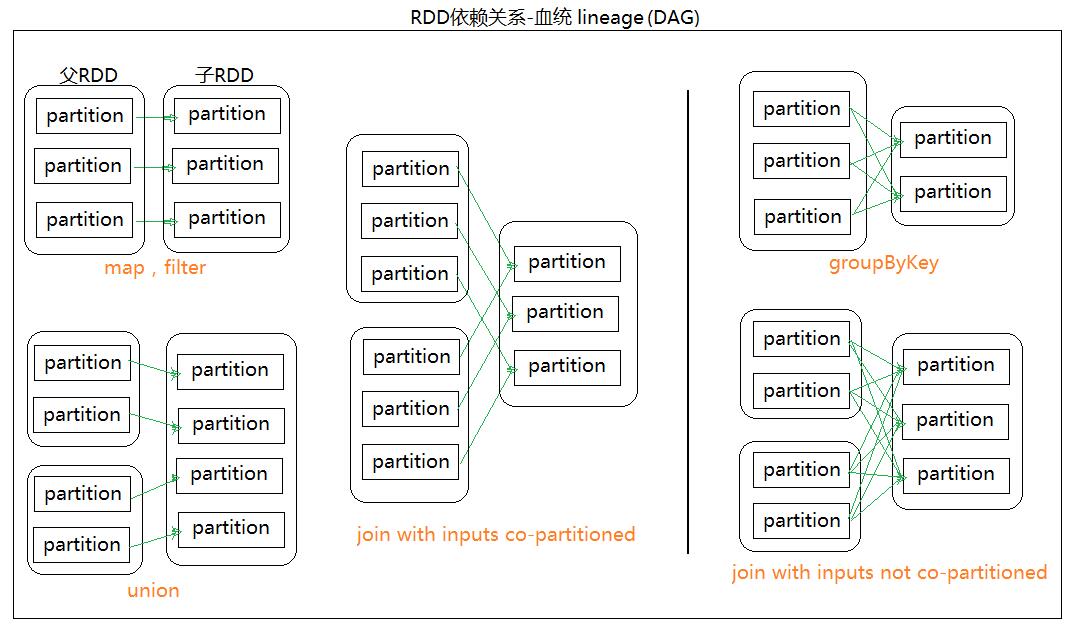
- 依赖的具体实现,以及怎么去知道是窄依赖还是宽依赖?
所有的依赖都要实现trait
Dependency[T]abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}窄依赖是有两种具体实现
OneToOneDependency和RangeDependencyabstract class NarrowDependencyT extends Dependency[T] {
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}//OneToOneDependency
class OneToOneDependencyT extends NarrowDependencyT {
override def getParents(partitionId: Int) = List(partitionId)//RangeDependency
class RangeDependencyT extends NarrowDependencyT {override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
}宽依赖的实现只有一种:
ShuffleDependencyclass ShuffleDependency[K, V, C] extends Dependency[Product2[K, V]] { … }
窄依赖|宽依赖,可以通过dependencies方法来查看,以上面的wordCount为例,可以看到res4(reduceByKey)为宽依赖

RDD依赖关系的划分(stage)
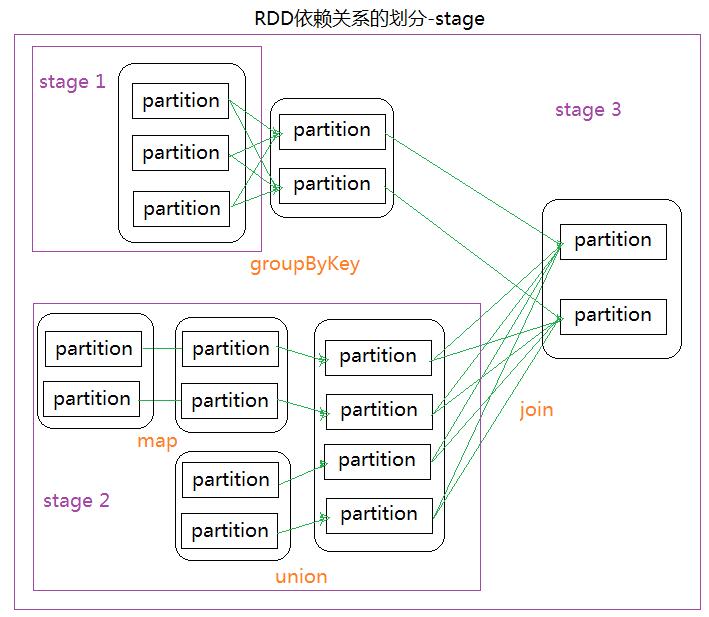
RDD依赖关系的划分,RDD怎么被划分到一个stage里面?
- 就是通过窄依赖和宽依赖来划分stage的
- 如果是窄依赖就他们放在一个Stage里面,遇到宽依赖就断开划分为另外一个stage
- 如上面的workCount例子,就划分为了两个stage,在reduceByKey的时候断开了
- 如下图,遇到groupByKey断开,为一个stage1,map、union为窄依赖遇到join断开划分为stage2,其余划分为stage3
- 参考: