
Spark Streaming--相关介绍
我接着 分享主题 往下看,上两篇主要介绍了Spark,本篇文章主要介绍Spark Streaming相关概念,有如下内容:
- (介绍的比较基础哈,大神就可以跳过了,对 Spark Streaming 相关的应用 可以看之前的博客)
- Spark Streaming 在计算引擎中的位置
- Spark Streaming 的介绍
- Spark Streaming 处理的数据流
- Spark Streaming 相关概念
Spark Streaming 在计算引擎中的位置
- 在分布式计算中,大致分为了两类:离线批处理和实时流计算(还有一种中间状态近实时计算)
离线批处理:以处理大批量数据为主,常常用于数据仓库中的ETL,对时效性相对要求不高(可以以分钟小时为单位)常见的框架有MapReduce、Spark job、FlinK DataSet;实时流计算:主要以小批量数据处理为主,对时效性相对要求高(以毫秒|秒为单位),最开始的Storm(JStorm)、最近火的Flink;近实时计算:还有一种在离线批处理和实时流计算中间的,就是该篇博客的主角了“Spark Streaming”,目前来讲它并非实时计算(Spark 2.2版本之后就很难讲了)。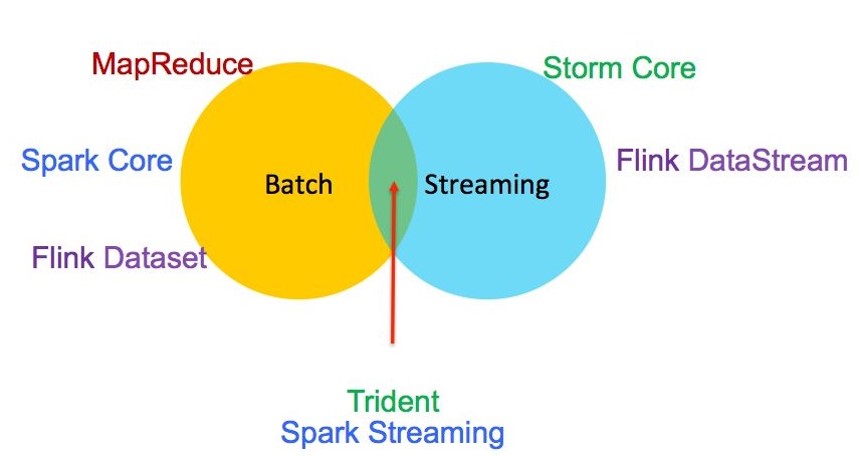
Spark Streaming 的介绍
Spark Streaming:基于Spark core的计算模型,Spark最开始只有Spark Core,之后的SQL\Streaming\MLib\Graphx 都是在Spark Core上面进行的扩展。- 那相比其他流计算框架 Spark Streaming 所具备的一些优势是什么呢?具体可参考:http://www.csdn.net/article/2015-09-13/2825689(PS:如果Flink普及之后,感觉Spark Streaming并没有太多优势)
- 能在故障报错与straggler的情况下迅速恢复状态;
- 更好的负载均衡与资源使用;
- 静态数据集与流数据的整合和可交互查询;
- 内置丰富高级算法处理库,可以很好的和SQL、机器学习、图处理结合,常说的在流上做机器学习,图处理等。
Spark Streaming整个计算流程大致描述就是:输入的数据通过Spark Streaming处理成一小批小批的数据,然后交给Spark Engine处理(Spark Engine 处理的数据封装就是RDD)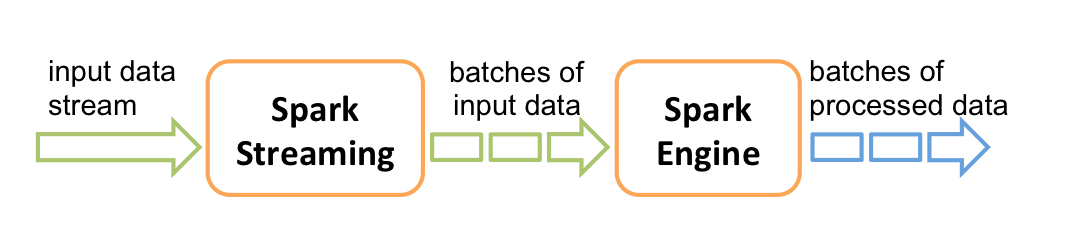
Spark Streaming 处理的数据流
Spark Streaming支持从多种数据源获取数据,包括 Kafka、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。- 在我们开发的时候引入相应的jar就可以了,比如source端是kafka,spark streaming作为消费者消费kafka数据就需引入
spark-streaming-kafka_2.xxeg: val kafkaMsg=KafkaUtils.createDirectStream(ssc, kafkaParams, fromOffsets, messageHandler)
Spark Streaming 相关概念
- 上面提到
Spark Streaming是基于Spark core的计算模型,其实底层组件还是核心RDD,只不过在Streaming这边是对RDD做了一层封装叫做DStream。
RDD:Spark最核心的概念(RDD详细讲解参考)DStream:对RDD的封装DStreams(Discretized Streams):一系列连续数据流的抽象。一系列:指的就是一段时间间隔(时间窗口)数据流:数据指的就是RDD(分布式数据集)
- (我看网上介绍Streaming概念就是大篇文字描述,这样感觉概念讲的不够简洁明了,倒还扰乱了你的思路!我喜欢各种表现形式,图片文字代码)
理解一下时间窗口和间隔时间,先看看代码1
2
3
4val sparkConf = new SparkConf()
.set("spark.streaming.kafka.maxRatePerPartition", maxRatePerPartition) //此处为每秒每个partition的条数
val ssc = new StreamingContext(sc, Seconds(timeWindow.toInt)) //多少秒处理一次请求时间窗口和间隔时间,因为streaming是处理小批量数据,把多少数据认为是一个批次呢?就是通过时间间隔来划分,让streaming job多久去处理一次(多久去消费一次数据)这段时间的相关计算可以理解成一个时间窗口。
- 怎么去设置相应的值,可参考:Streaming 任务的划分
